딥상어동의 딥한 SQL/LV2.중급쿼리
[MSSQL] 이전 값으로 NULL 값 대체하기
딥상어동의 딥한생각
2021. 8. 31. 11:09
0. 문제
SQL을 하다보면 문득 이런 고민에 빠질때가 있습니다.

저기 NULL값을 이전 값으로 대체하고 싶은데... 어떻게 하지?
왜냐하면, SQL에는 Pandas fillna 함수의 ffill과 같은 메서드가 없기 때문인데요.
https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.fillna.html
pandas.DataFrame.fillna — pandas 1.3.2 documentation
If method is specified, this is the maximum number of consecutive NaN values to forward/backward fill. In other words, if there is a gap with more than this number of consecutive NaNs, it will only be partially filled. If method is not specified, this is t
pandas.pydata.org


Row_number를 이용하면 쉽게 해결할 수 있습니다. (코드는 MSSQL 기준입니다.)
1. 샘플 테이블 생성
create table tb
(
id int
,num int
)
insert into tb
values
(1, 90661), (2, 97560), (3, 80744), (4, null), (5, null), (6, 23312), (7, 21345), (8, null), (9, null), (10, 21322)
select * from tb
2. NULL 이전 값으로 대체
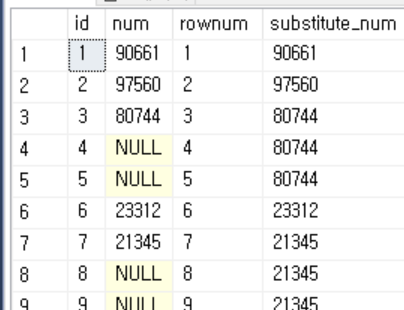
해결 방법은 다음과 같습니다.
1. row_number() 를 사용하여 id별로 인덱스를 생성한다.
2. num의 값이 null인 index는 이전 값의 index로 대체합니다.
3. 원본 테이블에서 index별로 값을 불러옵니다.
select *
, (
select num
from tb_rownum A
where A.rownum = (
-- null이전의 index == max
select max(b.rownum)
from tb_rownum b
-- null인 경우 null이전의 index를 가져옴
where b.rownum <= c.rownum
and b.num is not null
)
) as substitute_num
from tb_rownum c