


안녕하세요 신입 초보 분석가입니다. 데이터 분석을 공부하면서 고민이 됐던 내용들을 포스팅합니다.
github.com/GiblesDeepMind/deepPythonAnalysis
GiblesDeepMind/deepPythonAnalysis
I'm JDM! The man who will be the Analysis King! . Contribute to GiblesDeepMind/deepPythonAnalysis development by creating an account on GitHub.
github.com
개인 깃허브 페이지입니다(이거 하시는 분들 멋있어 보여서 따라해봤습니다.)
초록
[코드 페이지]
https://github.com/GiblesDeepMind/deepPythonAnalysis/tree/master/Preprocessing/Data%20Structure
[데이터 셋]
https://www.kaggle.com/nyphil/perf-history
[목차]
1. json이란?
2. json 파일 읽기
3. json_normalize
4. dataframe to json
5. final data merge
6. 소감
www.kaggle.com/nyphil/perf-history
NY Philharmonic Performance History
All Performances, 1842-Present
www.kaggle.com
해당 데이터 셋의 raw_nyc_phil.json을 사용했다. 데이터 셋은 그냥 다운 받을 수도 있고
Kaggle API를 통해 호출할 수도 있다. Kaggle Api 사용법은 아래 블로그에 잘 설명되어 있으니 참고하시길 바란다.
teddylee777.github.io/kaggle/Kaggle-API-%EC%82%AC%EC%9A%A9%EB%B2%95
Kaggle(캐글) API 사용법 - 데이터셋 다운로드와 제출을 손쉽게
Kaggle API를 활용하여 데이터셋 다운로드와 바로 제출하는 방법에 대하여 알아보겠습니다.
teddylee777.github.io
1. JSON(JavaScript Object Notation)이란
일반적으로 서버에서 클라이언트로 데이터를 보낼 때 사용하는 양식
- https://namu.wiki/w/JSON
(갓무위키에는 없는게 없다.) JSON이 뭐라고? 서버?클라이언트? 벌써 뭔가 복잡한데.. 내용을 요약하기 전에 나같은 초보분들에게는 다음 영화 3편을 추천한다. 시간이 되면 한번 보시길 추천한다. 건강에 좋은 영상들이다.
[서버와 클라이언트]
www.youtube.com/watch?v=yBPyzaccbkc&ab_channel=%EC%83%9D%ED%99%9C%EC%BD%94%EB%94%A9
[JSON 개념정리]
www.youtube.com/watch?v=FN_D4Ihs3LE&ab_channel=%EB%93%9C%EB%A6%BC%EC%BD%94%EB%94%A9by%EC%97%98%EB%A6%AC
[직렬화와 역직렬화]
www.youtube.com/watch?v=qrQZOPZmt0w&ab_channel=%EB%A0%88%ED%8A%B8%EB%A1%9Cretr0
단순하게 생각하면 JSON은 택배 포장지 같은 것이라고 생각할 수 있다.

ME(클라이언트)가 쇼핑몰(서버)에 주문(REQUEST)을 하면 쇼핑몰(서버)에서 ME(클라이언트)에게 주문 내용(데이터)을 JSON이라는 포장지에 담아서 전달해준다고 생각할 수 있다. 결론적으로, 이 글을 보는 사람들 입장에서는 JSON이 무엇인지 보다는 JSON은 일종의 포장지고 그 포장지 안에 내용물을 확인하는 방법이 더 중요하다고 할 수 있다.
API를 사용해본 사람들한테는 꽤 친숙한 개념이겠지만, 처음 본 사람이 있을 수도 있기 때문에 JSON에 대해서 나름 생각한바를 적어봤다.
그냥, 넘어가기는 좀 아쉬우니까 JSON에 대해 조금만 더 살펴보자.

위 이미지는 Kaggle API를 이용하는데 사용되는 username과 key를 포함하고 있는 json 파일이다. username과 key를 json이라는 포장지에 담아서 kaggle에 "나 확인된 유저인데 데이터좀 주쇼"라는 요청을 하는데 사용된다. 이러한 자료구조를 java에서는 map 자료구조라고 하는데 python의 dict와 비슷해보인다.
www.quora.com/Is-Javas-Map-data-type-the-equivalent-to-Pythons-dictionary
Is Java's Map data type the equivalent to Python's dictionary?
Answer (1 of 3): Yes and No. Yes at a high level: Python dictionary is implemented as hash tables underneath, so operations (get/put, bucketing) and performance (O(1) lookup) are similar to the HashMap implementation in Java. No: * Map is just an interface
www.quora.com
java의 Map과 python의 dict가 비슷하냐에 대한 유능하신 형님들의 답변에 따르면 "Yes and No" = 거의 비슷하다고 볼 수 있겠다. 약간의 차이점도 있다고 하니 정~말 심심하신 분들은 한번 읽어보시길
+크롤링을 해보신 분들이라면 XML이라는 파일에 대해서 들어봤을 건데 이것도 JSON과 같이 일종의 포장지라고 생각할 수 있다. 다만, 차이점이 있다면(나도 잘 모르고 적는거니 그냥 넘어가도 된다) XML에는 복잡한 헤더/태그 등이 있는 반면 JSON은 구조가 단순해서 Parsing(=일종의 포장지를 뜯는 행위)이 더 쉽다고 한다.
2. JSON 파일 읽기
2-1. pd.read_json
#https://riptutorial.com/ko/pandas/example/16714/json-%EC%9D%BD%EA%B8%B0
pd.read_json('[{"A" : 1, "B" : 2}, {"A" : 3, "B" : 4}]')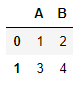
pd.read_json 사용 예시이다. 여기서, Pandas가 json 자료 구조를 어떻게 읽어오는지 알 수 있다.

이해를 돕기 위해 갓무위키의 JSON 구조 이미지를 들고 왔다. 즉, 저 "회사"라는 Key에 딸려있는 value들 [{}, {}]을 읽어오는 것이 pandas가 json 자료 구조를 읽어오는 방식이라고 할 수 있다.
pandas.pydata.org/pandas-docs/stable/reference/api/pandas.read_json.html
pandas.read_json — pandas 1.1.4 documentation
For on-the-fly decompression of on-disk data. If ‘infer’, then use gzip, bz2, zip or xz if path_or_buf is a string ending in ‘.gz’, ‘.bz2’, ‘.zip’, or ‘xz’, respectively, and no decompression otherwise. If using ‘zip’, the ZIP file
pandas.pydata.org
공식문서에 각종 파라미터들과 to_json으로 dataframe을 json으로 변환하는 방법까지 예시가 있으니 심심하면 한번 보시길
2-2. Json.load
with open("C:/Users/HOME/Dropbox/dataset/used/perf-history/raw_nyc_phil.json",'r') as json_file :
json_sample = json.load(json_file)
뒤에 후술하겠지만, json.load와 json.loads는 다르다. json.load는 json 파일을 통째로 들고오는 방법이다.
type(json_sample)
>> dict
json_sample.keys()
>> dict_keys(['programs'])아까, json이 key와 value를 가진 map구조라고 했다. json.load를 하게되면 그 파일은 dict 자료구조로 인식되고 그에 따라 keys()와 values() items()등 메서드를 사용할 수 있다.
json_sample.values()
대략 이런 어마무시한 괴물들이 'programs'라는 key에 들어있다고 생각하면 된다. 자세히 살펴보니 저 값들 안에도 'season' : '1842-43' -> key와 value 관계가 있는 것 같다.
json_sample['programs'].keys()
그래서 봤더니 엥? 에러가 뜨네?
type(json_sample['programs'])
>> list
type(json_sample['programs'][0])
>> dict
json_sample['programs'][0].keys()
>> dict_keys(['season', 'orchestra', 'concerts', 'programID', 'works', 'id'])왜냐하면, json_sample['programs']는 더 이상 dict 형이 아니기 때문이다. 즉, key를 통해 value list에 접근한 상황이라고 할 수 있다.
그래서, 위와 같이 한 깊이 더 들어가면 다시 keys()를 확인할 수 있다. 그럼, 이제 여기서 인덱스별로 반복문을 돌려 key와 value들을 뽑으면 될까?
json을 만만하게 보면 안된다. 후훗
json_sample['programs'][0]['works'][0]
한 뎁스 더 존재한다. 하지만, json의 깊이는 이게 끝이 아니다. 마음만 먹으면 더 깊게 만들 수도 있다.
genson
GenSON is a powerful, user-friendly JSON Schema generator.
pypi.org
간단하게 schema 구조를 확인할 때 이런 라이브러리를 쓸 수도 있다. 참고하시길
2-3. Json.loads
Json.loads는 json 파일 형태가 아니라 string 형태의 객체에서 json 형식 내용을 추출할 때 사용한다. 나의 경우 API를 호출할 때 사용해봤다.

API를 호출하는 대략적인 header 구조를 만들고
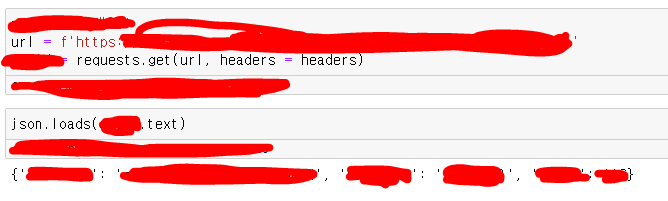
호출 객체(requests.get)에 .text 메서드를 사용하면 dict형 자료 구조를 볼 수 있다.
3. json_normalize
json_normalize는 이름만 봐도 그 역할을 짐작할 수 있다. normalize -> 뭔가 노멀하게 만든다는데 pandas에서 노멀하게 만드는건 뭘까? 바로 데이터프레임으로 만드는 것이다. 즉, json_normalize는 json에서 데이터프레임을 쉽게 생성하도록 도움을 주는 메서드라고 할 수 있다.
3-1. depth1
앞서 Pandas에서 json객체를 읽어오는 방식에 대해서 설명했다.
한번 더 복습하자면, Pandas에서는 빨간색 영역의 value들을 받아오는데 그러기 위해서는 "회사"라는 key를 가지고 value에 접근해야 한다.
json_data = pd.json_normalize(json_sample['programs'])json_sample이라는 객체에 'programs'라는 key를 이용해 접근하면
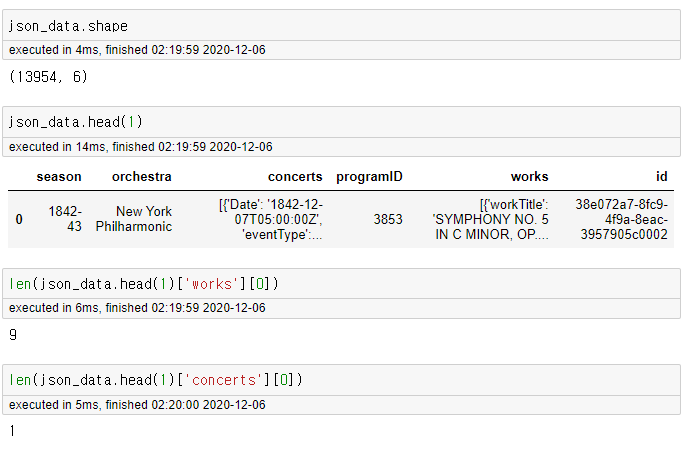
위와 같이 json 객체를 데이터프레임으로 만들 수 있다. 근데, 잠깐 저거를 바로 쓸 수 있을까? 당장, works와 concerts만 봐도 [] 안에 덕지 덕지 dict 형 자료들이 보인다.
sample 데이터로 살펴보니 concerts는 하나고 works는 9개인데 한 콘서트에서 여러 작업이 있었다고 생각할 수 있다. 쟤네를 풀어줘야 한다.
3-2. depth2
works_data = pd.json_normalize(data=json_sample['programs'],
record_path = 'works',
meta=['season', 'orchestra', 'programID', 'id'])
#id명 변경
works_data.rename(columns = { 'ID': 'workTitle_ID', 'id' : 'work_ID'}, inplace=True)아까 보지 못했던 record_path와 meta 파라미터 두 개가 추가됐다.
json_sample['programs'][0].keys()
>> dict_keys(['season', 'orchestra', 'concerts', 'programID', 'works', 'id'])참고차 다시 key값을 들고 왔다. 앞서, sample로 확인한 데이터에서 ['works'][0] 안에 9개의 {} 들이 들어있다고 했다. 그래서, 이 데이터를 올바르게 풀기 위해서는
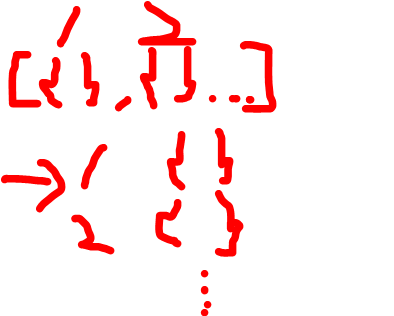
위와 같은 작업을 해야한다. 이해가는가?
record_path : decode 해줘야할 열 지정 [{}, {}, {} ....]
meta : decode 하는 열과 동일 차원에 존재하는 열들 중 데이터 프레임에 포함시킬 열 선택
다시, key 구조를 보며 풀어 설명하자면 [{}, {}, {}, ...] 와 같이 생긴 works를 경로에 record_path 접속해서 decode하고
json_sample['programs'][0].keys()
>> dict_keys(['season', 'orchestra', 'concerts', 'programID', 'works', 'id'])동일 차원에 존재하는 다른 열들 -> season, orchestra, programID, id 을 meta로 사용하겠다는 뜻이다. meta로 사용한다는 뜻은 예시를 보면 쉽게 이해할 수 있다.
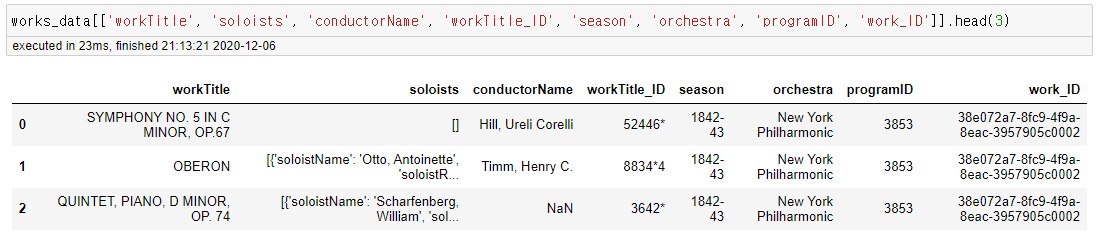
자세히보면 여러 workTitle에 대해 동일한 season, orchestra, programID, id가 반복되는 것을 알 수 있다.
season, orchestra, ..... workTitle1
..... workTitle2
..... workTitle3
..... 이런느낌
따라서, 특정 시즌 프로그램에서 진행한 여러 곡들을 본 작업을 통해 decode 했다고 할 수 있다.
concerts_data = pd.json_normalize(data=json_sample['programs'],
record_path = 'concerts',
meta=['programID', 'id'])
#id명 변경
concerts_data.rename(columns = {'id' : 'work_ID'}, inplace=True) 콘서트 관련 정보도 비슷한 과정을 거치면 된다. 그런데, 여기서 문제가 하나 있다. 예시에서 soloists를 보아라. 저녀석을 또 풀어줘야 한다. 다행히 rocord_path에 list를 사용할 수 있다.
soloists_data = pd.json_normalize(data=json_sample['programs'],
record_path=['works', 'soloists'],
meta=['ID', 'programID'])여기서 record_path의 의미는 works로 접속 -> soloists의 값들을 decode 해주겠다는 의미이다.
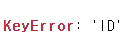
그런데, 여기서 KeyError가 난다. 왜일까? works -> soloists로 한 뎁스 더 들어가게 되면서 ID와 programID가 더 이상 같은 차원에 존재하지 않게 된 것이다.
사실, meta만 적당히 조절해서 마무리할 수도 있다. 하지만, soloists에 programID와 ID가 없다는 것은 꽤 큰 문제이다.
왜일까? 두 값이 없다면 어느 공연의 어느 workTitle에서 누가 soloists였는지를 알 수 없기 때문이다.
따라서, 다른 전처리 방법이 필요하다.
4. dataframe to json
굉장히 쉬운 해결책이 있다. 바로, 저 데이터프레임을 다시 JSON으로 만드는 것이다. 왜?
다시 반복, 저 빨간 영역안에 soloists까지 포함시키기 위해서이다. (굳이 따지자면, 이름, 운영체제, soloists....)
test = works_data.to_json(orient='table')
parsed = json.loads(test)
parsed.keys()
>> dict_keys(['schema', 'data'])works_data를 json화 하고 그 파일을 다시 json.loads로 파싱한다. 여기서 json.loads를 사용한 이유는 우리가 다루는 데이터가 더이상 파일이 아니기 때문이다.
여기서, 데이터 프레임을 json으로 변환할 때 크게 schema와 data 두 키가 생성되는 것을 알 수 있다.
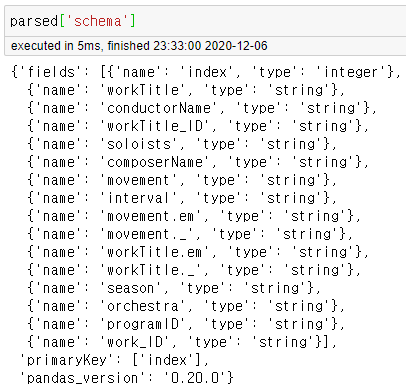
schema에서는 json 스키마 구조를 보여준다. 의도한대로 soloists열이 같은 차원에 존재하는 것을 알 수 있다.
soloists_data = pd.json_normalize(data=parsed['data'],
record_path=['soloists'],
meta=['workTitle_ID', 'programID', 'work_ID'])
짠, 아주 예쁘게 변환이 되었다. 여기서 잠깐
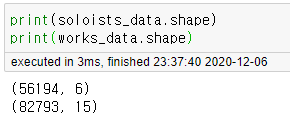
원본 테이블과 행의 수가 다른데
works_data_test = works_data.copy()
works_data_test['len_soloists'] = works_data_test.soloists.map(lambda x : len(x))
works_data_test['len_soloists'].sum()
>> 56194위 코드 결과에서 works_data의 soloists에서 [] empty list로 표기되던 값이 자동으로 제거됐다는 사실을 알 수 있다.
5. final merge
semi_final = works_data.drop('soloists', axis=1).merge(soloists_data,
left_on=['workTitle_ID', 'programID', 'work_ID'],
right_on=['workTitle_ID', 'programID', 'work_ID'],
how='left')
semi_final = semi_final.drop_duplicates()
final = semi_final.merge(concerts_data,
left_on = ['programID', 'work_ID'],
right_on = ['programID', 'work_ID'],
how = 'left')
final.drop_duplicates(inplace=True) works_data를 기준 테이블로 soloists_data와 concerts_data를 합쳤다. how='left'인 이유는 works_data를 보존하기 위해서이다. 그리고, merge할때마다 행이 점점 늘어나는데 한 workTitle에 여러 soloists가 있을 수도 있고 같은 programID라도 eventtype이 다르거나 등의 경우가 발생할 수 있다.
중복을 제거하고자 중간 중간 drop_duplicates를 사용하였다.
import uuid
uuid_list = [uuid.uuid4() for i in range(final.shape[0])]
final['key'] = uuid_list
#각 일련번호가 유니크하게 부여됐는지 확인
len(final['key'].unique()) == final.shape[0]
>> True
정말, 마지막으로 각 행별 고유 일련번호를 부여했다. 이렇게 최종 데이터프레임을 완성하였다.
6. 소감
전처리 너무 어려웡 ㅠ

요런 형태를 nested dictionary initialization이라고 하는데 본 글의 트릭을 사용하면
play_arrow
brightness_4
# rows list initialization
rows = []
# appending rows
for data in list:
data_row = data['Student']
time = data['Name']
for row in data_row:
row['Name']= time
rows.append(row)
# using data frame
df = pd.DataFrame(rows)
# | https://www.geeksforgeeks.org/python-convert-list-of-nested-dictionary-into-pandas-dataframe/이렇게 반복문을 사용하지 않고도 문제를 해결할 수 있다.
'딥상어동의 딥한 데이터 처리 > 전처리' 카테고리의 다른 글
| [Pandas] 이것만은 알고가자 - 0.파일 불러오기 (0) | 2021.06.05 |
|---|---|
| 시계열 | 이동 평균(Moving Average) 기초 (0) | 2021.05.02 |
| Pandas | Melt (0) | 2021.03.02 |
| Pandas | Stack VS Unstack (2) | 2021.01.28 |
| 아카이브 페이지 (0) | 2020.12.06 |
제 블로그에 와주셔서 감사합니다! 다들 오늘 하루도 좋은 일 있으시길~~
포스팅이 좋았다면 "좋아요❤️" 또는 "구독👍🏻" 해주세요!


