![[Python] np.where을 이용하여 두 개의 데이터프레임 전체를 비교하기](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FMR3DF%2FbtrrpTH3Rqq%2FyAr3oQcz5g8VLvYN0h13U0%2Fimg.png)

[Python] np.where을 이용하여 두 개의 데이터프레임 전체를 비교하기딥상어동의 딥한 데이터 처리/전처리2022. 1. 23. 13:37
Table of Contents
0. 비교 조건
1. 데이터 프레임 전체 원소들을 비교할 것
2. 벡터 연산을 사용할 것
3. 두 데이터 프레임의 Shape과 행/열 인덱스읠 배열 순서는 동일하다고 가정할 것
1. 비교 목표
두 개의 데이터프레임 전체를 비교하고 각 원소별로 minimum한 값을 리턴한다.
2. 코드 설명
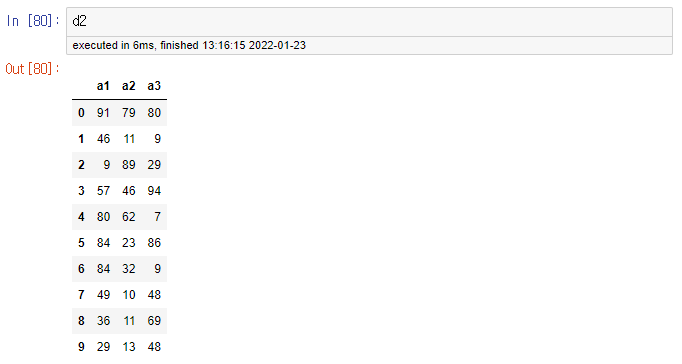
1. 우선, 동일한 shape의 두 데이터 프레임 객체를 만들어 준다.
import pandas as pd
import numpy as np
d1 = pd.DataFrame()
d2 = pd.DataFrame()
d1['a1'] = np.random.randint(1, 100, 10)
d1['a2'] = np.random.randint(1, 100, 10)
d1['a3'] = np.random.randint(1, 100, 10)
d2['a1'] = np.random.randint(1, 100, 10)
d2['a2'] = np.random.randint(1, 100, 10)
d2['a3'] = np.random.randint(1, 100, 10)
2. 데이터프레임 객체를 2d array로 변경해준다.
d1_np = d1.to_numpy()
d2_np = d2.to_numpy()
3. np.where을 이용하여 데이터 프레임 전체 원소들을 비교한다.
np.where(d1_np >= d2_np, d2_np, (np.where(d1_np < d2_np, d1_np, 999)))- 해석하자면, d1_np가 d2_np보다 크거나 같은 경우 d2_np를 반환한다.
- 왜냐하면, d2_np가 더 작은 값이기 때문이다.
- else인 경우 d1_np < d2_np인 조건을 넣어주고 d1_np를 반환한다.
- 왜냐하면, 다시 d1_np가 작은 값이 되기 때문이다.
999는 파라미터 개수를 채우기 위해 넣는 값이다. 두 배열의 값들이 모두 숫자인 경우 999가 나올 일은 없다.
실제 값을 살펴보자.

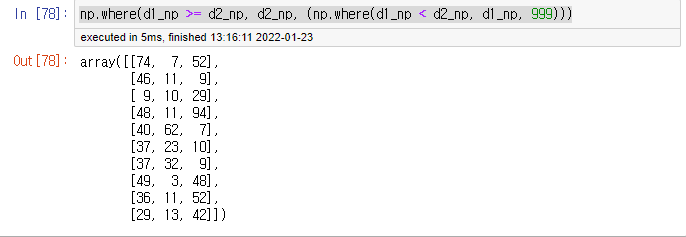
값들이 잘 배열된 것을 알 수 있다.
4. 데이터프레임 할당
df = pd.DataFrame(np.where(d1_np >= d2_np, d2_np, (np.where(d1_np < d2_np, d1_np, 999)))
, columns=['new_co1', 'new_col2', 'new_col3'])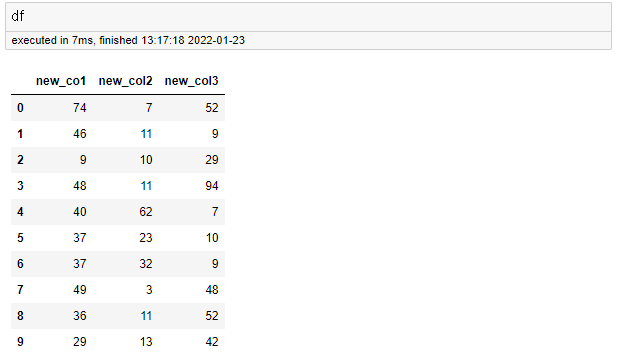
마지막으로 데이터프레임에 할당해주면 완성
'딥상어동의 딥한 데이터 처리 > 전처리' 카테고리의 다른 글
| [Pandas] 수치형 컬럼과 범주형 컬럼 구분하기 (0) | 2022.07.29 |
|---|---|
| [Pandas] Pandas_flavor로 Pandas API method 추가해보기 (2) | 2022.03.13 |
| [Pandas] 판다스에서 SQL 윈도우 함수 사용해보기 (0) | 2021.12.27 |
| 정규표현식 뽀개기 (3) - 반복 하기 (0) | 2021.10.24 |
| 정규표현식 뽀개기 (2) - 메타 문자 이해하기 (0) | 2021.10.24 |
@딥상어동의 딥한생각 :: 딥상어동의 딥한생각
제 블로그에 와주셔서 감사합니다! 다들 오늘 하루도 좋은 일 있으시길~~
포스팅이 좋았다면 "좋아요❤️" 또는 "구독👍🏻" 해주세요!
![[Pandas] 수치형 컬럼과 범주형 컬럼 구분하기](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FbHtiyD%2FbtrIpGMTY23%2Flf0Zv7dZQuTZ2Wk5oYKq7k%2Fimg.png)
![[Pandas] Pandas_flavor로 Pandas API method 추가해보기](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2Ftvo1J%2FbtrvJ9goj3Z%2F0qSZMTqu4Hxi3jFZf0UHs1%2Fimg.png)
![[Pandas] 판다스에서 SQL 윈도우 함수 사용해보기](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FdQ40NE%2Fbtro6bXFrr7%2FpM3k9KIuJKThwtwVk32tGk%2Fimg.png)
