![[데이터로 보는 주식] 물타기 도대체 언제 할것이냐, 그것이 문제로다.](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FcwSURB%2FbtrmZH6deg6%2FatvH4xsdsuoaPKxFMiL0f0%2Fimg.png)

0. 들어가며
안녕하십니까 파란불 달인 딥상어동입니다. 왜 파란불이라는 말을 썼을까요?

그것은 바로바로. 제 주식 포트 폴리오에 "음봉"이 가득~ 하기 때문인데요. 제 손으로 적기는 정말 슬픕니다만.. 음봉은 = 손실이라는 뜻입니다. 이렇게 주가가 하락할 때, 대다수 사람들이 고민하는 것은 "평단가"인데요. 주가가 하락할때마다 주식을 추가 매수 하는 것을 전문 용어로 "물타기"라고 합니다.

위 짤보다 물타기를 더 잘설명해줄 수 있을까? 싶네요.


사실, 물타기에 특별한 전략이 있다기 보다는(저의 기준) 그저 "다음날은 오르겠지" 라는 기대감 때문에 물타기를 한다고 생각합니다. 어쨌든, 이번주도 여느날처럼 뇌를 거치지 않은 매수를 할 뻔 하다가 문득 이런 생각이 들었습니다.
지금 물을 타는게 과연 좋은 타이밍일까?
1. 모멘텀이란?
사실, 물타기가 좋지 않다는 건 이미 관행적으로 알려진 사실입니다. 그 이유는 주식 시세에는 항상 "모멘텀"이라는게 작용하기 때문인데요. "모멘텀"이란 주가의 상승과 하락에 있어 가속도와 관련된 용어입니다.
모멘텀 - 관성
관성이라는 단어로도 생각해볼 수 있을 것 같습니다. 즉, 이전 시기에 가해지던 힘의 영향을 얼마나 받았냐라고도 할 수 있겠네요(물알못).
모멘텀
상승장 - 상승 중이니까 계속 상승하겠지?
하락장 - 하락 중이니까 계속 하락하겠지?
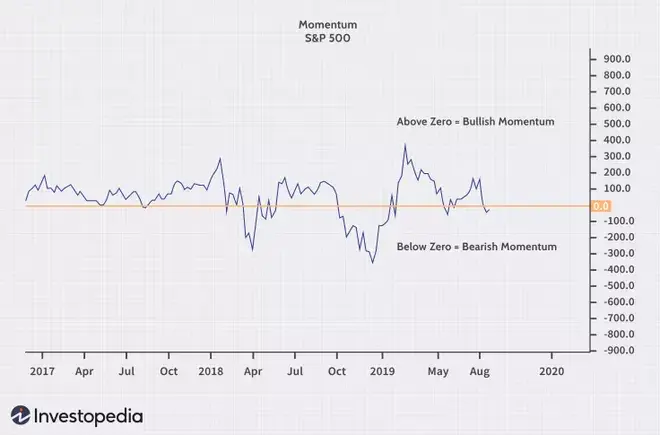
위 그림은 S&P 500의 Momentum Indicator 그래프입니다. 주목하셔야 할 것은 0 라인을 기준으로 0 이상인 일자들과 0 미만인 일자들이 몰려 있는 것을 확인할 수 있는데요. 이를 모멘텀이라고 할 수 있습니다. 즉, 주식시장에서 "모멘텀" 은 이미 존재하는 현상이며, 듀얼 모멘텀 등 관련된 다양한 전략들도 있는 것으로 알고 있습니다.
2. 개미가 물타기를 할 때 조심해야 할 것은?

주식시장에는 유명한 명언이 있죠. "무릎에서 사서 어깨에서 팔아라"

제가 대표적으로 물려있는 종목 중 하나인 팬오션 인데요^^.... 저 같은 개미 분들의 심리란.. "이 쯤이면 무릎이겠지...?", "이 쯤이면 무릎이겠지....?" 이러다가 매수를 하지 않으실까 싶네요.


그러다가, 주식이 오른날은 행복해하고 떨어지면 불행해하고... 그게 저와 같은 개미 분들의 숙명이 아닐까 싶습니다. (주륵) 어쨌든, 중요한 것은
물타기를 하는 타이밍
이라고 생각합니다. 이왕이면 충분히 떨어졌을만큼 떨어졌을 때, 물타기를 하는게 좋겠죠.
3. 분석 과정
분석 대상
종목 : KTOP30 구성 종목
https://www.kodex.com/product_view.do?fId=2ETF55
KODEX
코덱스 공식홈페이지, 증권사 리포트모음, 대한민국 ETF 시장의 선도자, KODEX는 국내 시장을 뛰어넘어 글로벌 시장을 선도하는 ETF 운용사를 지향합니다.
www.kodex.com
분석 로직
1. 코스피 TOP30 종목의 기준 일자를 선택한다.
2. 기준 일자 이전 30일 간의 종가를 살펴본다.
3. 종가를 기준으로 2를 소팅 했을 때, 기준 일의 종가가 상위 몇 %인지 살펴 본다.
그룹을 10개로 나눠 본다.
그룹은 크게 5개다.
머리 : 이전 30일 기준 기준 일 종가 상위 20% 이내
어깨 : 이전 30일 기준 기준 일 종가 상위 20% ~ 40% 이내
허리 : 이전 30일 기준 기준 일 종가 상위 40% ~ 60% 이내
무릎 : 이전 30일 기준 기준 일 종가 상위 60% ~ 80% 이내
발 : 이전 30일 기준 기준 일 종가 상위 80% ~ 100% 이내
4. 그룹별로 기준 일자 이후 30일 데이터를 살펴본다.
5. 기준 일자의 종가 대비 가격이 상승한 일자가 며칠이나 되는지 비율을 살펴 본다.
6. 30일 모두 상승했으면 100%로 집계 된다.
예를 들어, 12/3 팬오션의 주가는 이전 30일 대비 바닥이라고 할 수 있겠네요. (주륵)
4. 분석 결론 - 물은 신중하게 타자
KTOP30 종목에서 코로나 이전 2019년도의 종가를 일자별로 무작위로 뽑고 종가가 이전 30일 간의 가격 대비 어느 정도 위치인지(머리, 어깨, 허리, 무릎 발)에 따라 이후 30일 간 기준일 종가 대비 상승한 일자가 며칠이나 되는지 그 비율을 살펴봤습니다.
아래에서 100%는 이후 30일간 하루도 빠짐없이 가격이 오른 경우를 나타냅니다. 따라서, 100%에 가까울수록 기준일 종가 대비 가격이 상승한 날들이 많았다라고 할 수 있습니다.
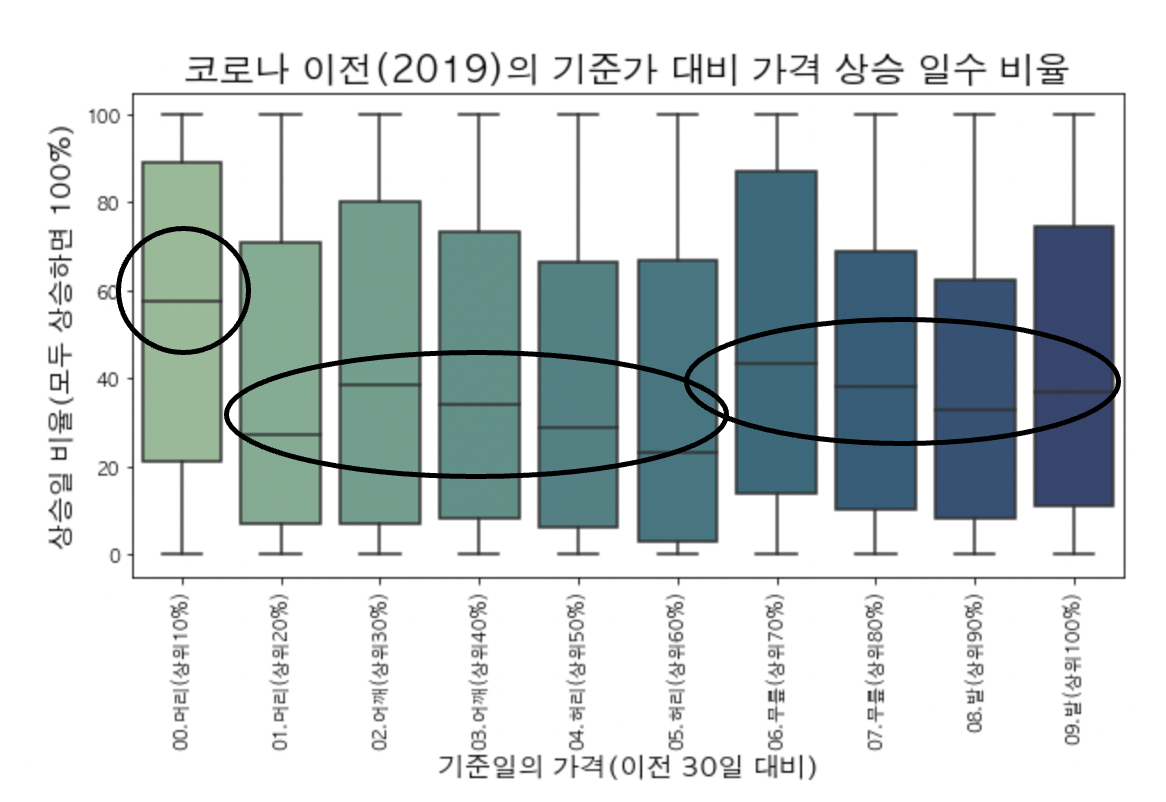
기준 일자의 종가가 이전 30일 대비 어느정도 수준인지 확인해보고, 이후 30일 동안 종가 대비 상승한 일 수 비율이 얼마나 되는지 살펴 봤습니다. 크게 3가지 그룹으로 나눠서 볼 수 있을 것 같은데요.
| 기준가 그룹명 | 상승일 수 비율 |
| 1.머리(상위10%) | 상승일 비율 중앙값 60% |
| 2.머리~어깨~허리 | 상승일 비율 중앙값 20%~40% |
| 3.무릎~발 | 상승일 비율 중앙값 40~50% |
1번 그룹의 경우 기존 가격 상승 추세를 지키며 상승하는 일이 많다고 할 수 있고 2번 그룹의 경우 본격적인 하락세가 시작된 시기라고 할 수 있는데요. 이때는 오히려 가격이 하락하는 일수가 더 많을거라고 생각할 수 있습니다. 3번 그룹의 경우 2번 그룹에 비해서는 종가 대비 상승 일 수가 높습니다. 즉, 하락세가 어느정도 진행된 이후의 시기에는 하락세가 본격적으로 진행되는 시기에 비해 반등 가능성이 좀 더 높다고 할 수 있습니다.
상자의 75%지점 바닥을 살펴 봤을 때, 05.허리(상위70%) 구간이 가장 낮은데요. 이는 충분히 하락했다고 생각하는 지점에서 이전보다 하락세가 더 가속화될 수 있음을 나타내지 않을까? 라고 생각했습니다.
결론적으로, 위 그래프가 시사하는 바는 "어중간한 지점(어깨 ~허리) 에서 물타기를 하는 것 보다는 가격 추세를 충분히 오랜 기간 살펴보고 하락이 충분히 진행된 시점(무릎~발)에 물을 타는게 더 낫다"라고 할 수 있습니다.
왜냐하면, 어중간한 시점에 물을 탈 경우 물타기를 한 가격보다 더 떨어지는 날을 볼 가능성이 높기 때문입니다.

똑 같은 그래프를 연도만 바꿔 코로나 직후인 2020년도 기준 데이터를 통해 그려봤는데요. 코로나 시기의 경우 상승일 비율 중앙값이 모두 80% 이상인 것을 알 수 있습니다. 종목별로 편차가 분명히 있겠습니다만, 어느 시기에 주식을 샀어도 가격이 올랐을 것이라는 것을 살펴볼 수 있습니다.
또한, 평균을 놓고 봤을 때, 기준가 그룹과 음의 상관 관계를 보이는데요. 즉, 기준가가 이전 한달 간의 가격에서 상위(머리~어깨)에 위치할수록 상승이 가속화되었을 것으로 추측해 볼 수 있습니다.
어쨌든, 오늘의 결론은 "함부로 물을 타지 말자. 물을 탈 때는 신중하게 가격 추이를 지켜보자." 입니다. 그리고, 본 분석 결과는 그저 재미로만 봐주셨으면 합니다.^^
5. 전처리 과정
라이브러리 세팅
import pandas as pd
import numpy as np
import pandas_datareader as pdr
from datetime import datetime, timedelta
import radar
import random
import statsmodels.formula.api as sm
from collections import defaultdict
from tqdm import tqdm
from joypy import joyplot
import matplotlib.pyplot as plt
from matplotlib import cm
import seaborn as sns
import scipy.stats as ss
from sklearn.preprocessing import Normalizer
import matplotlib
matplotlib.rcParams['axes.unicode_minus'] = False
from matplotlib import rc
rc('font', family='AppleGothic')
KTOP30 종목 리스트(KRX 정보시스템 참조)
kospi_list = pd.read_csv("코스피30.csv", encoding='cp949')
#0을 포함한 6자리 형태로 변환
kospi_list['종목코드'] = kospi_list['종목코드'].map('{:06d}'.format)
분석 함수 생성
def randomStocks(cntStocks: int):
"""
랜덤하게 종목 선정
"""
return random.sample(kospi_list['종목코드'].tolist(), cntStocks)
def getDateList(startDate : str, endDate : str, code: str, cntDays: int):
"""
yahoo 패키지의 경우 빈 값이 많음 이에 따라 값이 있는 데이터들에서
랜덤하게 날짜를 추출해 보기로 함
"""
stockDf = pdr.get_data_yahoo(f'{code}.ks', f'{startDate}', f'{endDate}')
return random.sample(stockDf.index.tolist(), cntDays)
def getStockDf(code: str, dateList: list, dayInterval : int):
"""
종목별 데이터셋 생성
"""
min_datetime_minusN = (min(dateList) + timedelta(days = -dayInterval)).strftime("%Y-%m-%d")
max_datetime_plusN = (max(dateList) + timedelta(days = +dayInterval)).strftime("%Y-%m-%d")
return pdr.get_data_yahoo(f'{code}.ks', f'{min_datetime_minusN}', f'{max_datetime_plusN}')
def getStockValue(baseDate: datetime, stockDf: pd.DataFrame):
"""
1. 기준일자의 종가를 구합니다.
2. 기준일자 이전 한달 동안 종가중 기준일자의 종가가 상위%인지 체크합니다.
3. 기준일자 이후 한달 간의 종가가 기준일자의 종가보다 높은지 낮은지 체크합니다.
4. 기준일자 이후 한달 간의 종가 기울기를 구해봅니다.
"""
baseDate_str = baseDate.strftime("%Y-%m-%d")
stockDf = stockDf
#1. baseDate의 값 위치
stockDf_before = stockDf.loc[(stockDf.index <= baseDate_str),].copy()
stockDf_before['rank_pct'] = pd.qcut(stockDf_before['Close'], q=10, labels= range(10, 0, -1))
#1. Output
stockDf_baseDate_rank = stockDf_before[stockDf_before.index == f"{baseDate_str}"]["rank_pct"][0]
stockDf_baseDate_Close = stockDf_before[stockDf_before.index == f"{baseDate_str}"]["Close"][0]
#2. baseDate 이후의 종가가 baseDate의 종가보다 높거나 낮은 일수
stockDf_after = stockDf.loc[(stockDf.index > baseDate_str),].copy()
stockDf_after['basePrice'] = stockDf_baseDate_Close
stockDf_after['priceGroup'] = stockDf_after['Close'].map(lambda x : 1 if x > stockDf_baseDate_Close else 0)
upperCnt = sum(stockDf_after['priceGroup'].tolist())
totalCnt = len(stockDf_after['priceGroup'].tolist())
#2. Output
probUpperCnt = int((upperCnt/totalCnt)*100)
#3. baseDate 이후의 주가 기울기
min_date = min(stockDf_after.index.tolist()).date()
stockDf_after['timeIndex'] = stockDf_after.index
stockDf_after['timeIndex'].rank(ascending=True)
regResult = sm.ols(formula = "Close ~ timeIndex", data = stockDf_after).fit()
#3, Ouput
regSlope = regResult.params[1]
return stockDf_baseDate_rank, probUpperCnt, regSlope
def getStockValList(cntStocks: int, startDate : str, endDate : str, cntDays: int, dayInterval: int ):
val_list = []
stock_list = randomStocks(cntStocks = cntStocks)
"""
종목과 일자별로 상승일수 비율과 기울기, 기준가 그룹을 뽑습니다.
"""
for stock_val in stock_list:
try :
date_list = getDateList(startDate = startDate, endDate = endDate
, code = stock_val, cntDays = cntDays)
stock_df = getStockDf(code = stock_val, dateList = date_list, dayInterval = dayInterval)
except Exception:
print("*"*50, "stock_error", "*"*50)
print(f"Error {kospi_list.loc[(kospi_list['종목코드'] == stock_val), '종목명']}")
pass
for date_val in date_list:
try :
resultVal_list = getStockValue(baseDate = date_val, stockDf = stock_df)
val_list.append(resultVal_list)
except Exception:
print("*"*50, "date_error", "*"*50)
print(f"Error {kospi_list.loc[(kospi_list['종목코드'] == stock_val), '종목명']} {date_val}")
pass
return val_list, stock_list
데이터 셋 구성
val_list_2019 = getStockValList(30, '2019-02-01', '2019-11-30', 90, 30)[0]
stock_list_2019 = getStockValList(30, '2019-02-01', '2019-11-30', 90, 30)[1]
val_list_2020 = getStockValList(30, '2020-02-01', '2020-11-30', 90, 30)[0]
stock_list_2020 = getStockValList(30, '2020-02-01', '2020-11-30', 90, 30)[1]
df_2019 = pd.DataFrame(val_list_2019, columns = ['percentile_group', 'upper_prob', 'slope'])
df_2020 = pd.DataFrame(val_list_2020, columns = ['percentile_group', 'upper_prob', 'slope'])
def getLabel(s):
if s == 1:
return '00.머리(상위10%)'
elif s == 2:
return '01.머리(상위20%)'
elif s == 3:
return '02.어깨(상위30%)'
elif s == 4:
return '03.어깨(상위40%)'
elif s == 5:
return '04.허리(상위50%)'
elif s == 6:
return '05.허리(상위60%)'
elif s == 7:
return '06.무릎(상위70%)'
elif s == 8:
return '07.무릎(상위80%)'
elif s == 9:
return '08.발(상위90%)'
elif s == 10:
return '09.발(상위100%)'
df_2019['NewLabel'] = df_2019['percentile_group'].apply(getLabel)
df_2020['NewLabel'] = df_2020['percentile_group'].apply(getLabel)
df_2019['Stan_slope'] = ss.zscore(df_2019['slope'])
df_2020['Stan_slope'] = ss.zscore(df_2020['slope'])
transformer_2019 = Normalizer().fit([df_2019['slope'].tolist()])
transformer_2020 = Normalizer().fit([df_2020['slope'].tolist()])
df_2019['Normal_slope'] = transformer_2019.transform([df_2019['slope'].tolist()])[0]
df_2020['Normal_slope'] = transformer_2020.transform([df_2020['slope'].tolist()])[0]
#라벨 정렬
list_label = df_2019['NewLabel'].unique().tolist()
list_label.sort()
그래프
plt.figure(figsize=(10,5))
ax_box_2019 = sns.boxplot(x="NewLabel", y="upper_prob", data=df_2019, palette = "crest")
ax_box_2019.set_xticklabels(list_label,rotation=90)
ax_box_2019.set_title("코로나 이전(2019)의 기준가 대비 가격 상승 일수 비율", fontsize = 20)
ax_box_2019.set_xlabel("기준일의 가격(이전 30일 대비)", fontsize = 15)
ax_box_2019.set_ylabel("상승일 비율(모두 상승하면 100%)", fontsize = 15);
plt.figure(figsize=(10,5))
ax_box_2020 = sns.boxplot(x="NewLabel", y="upper_prob", data=df_2020, palette = "flare")
ax_box_2020.set_xticklabels(list_label,rotation=90, fontsize = 13)
ax_box_2020.set_title("코로나 시기(2020)의 기준가 대비 가격 상승 일수 비율", fontsize = 20)
ax_box_2020.set_xlabel("기준일의 가격(이전 30일 대비)", fontsize = 15)
ax_box_2020.set_ylabel("상승일 비율(모두 상승하면 100%)", fontsize = 15);
Ref.
https://www.investopedia.com/articles/technical/081501.asp
Momentum Indicates Stock Price Strength
Momentum is the speed at which security prices change. It can be used in conjunction with other tools as an effective buy or sell indicator.
www.investopedia.com
http://data.krx.co.kr/contents/MDC/MDI/mdiLoader/index.cmd?menuId=MDC0204#
KRX 정보데이터시스템
증권·파생상품의 시장정보(Marketdata), 공매도정보, 투자분석정보(SMILE) 등 한국거래소의 정보데이터를 통합하여 제공 서비스
data.krx.co.kr
https://wendys.tistory.com/174
[Python] pandas_datareader를 이용하여 주식 데이터 가져오기! Yahoo Finance
저번 시간에 pandas를 이용하여 한국 거래소(KRX)의 주식 종목 코드를 가져왔었는데요, 이번에는 코스피(KOSPI), 코스닥(KODAQ) 주식 종목 코드를 이용하여 원하는 회사의 주식 정보를 가져와보려 합니
wendys.tistory.com
http://www.yes24.com/Product/Goods/90578506
파이썬 증권 데이터 분석 - YES24
투자 기법과 프로그래밍 기술로 자신만의 퀀트 투자 시스템을 완성하라『파이썬 증권 데이터 분석』은 웹 스크레이핑으로 증권 데이터를 주기적으로 자동 수집, 분석, 자동 매매, 예측하는 전
www.yes24.com
'딥상어동의 딥한 데이터 분석' 카테고리의 다른 글
| [Python] google maps API 가격 정책과 사용법 (0) | 2022.09.18 |
|---|---|
| [텍스트 분석] 파이썬으로 이청준 작가님 눈길 다시보기 (0) | 2021.10.10 |
제 블로그에 와주셔서 감사합니다! 다들 오늘 하루도 좋은 일 있으시길~~
포스팅이 좋았다면 "좋아요❤️" 또는 "구독👍🏻" 해주세요!
![[Python] google maps API 가격 정책과 사용법](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FbY9vik%2FbtrMkuItB5h%2FE5PzmN5c59cxVR9R5pkYL1%2Fimg.png)
![[텍스트 분석] 파이썬으로 이청준 작가님 눈길 다시보기](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2Fb5xxPr%2FbtrhlzdCZNQ%2Fr7tekQnNy9i9X8FqImj2H1%2Fimg.jpg)