![[텍스트 분석] 파이썬으로 이청준 작가님 눈길 다시보기](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2Fb5xxPr%2FbtrhlzdCZNQ%2Fr7tekQnNy9i9X8FqImj2H1%2Fimg.jpg)

0. 들어가며
나는 국어를 참 잘 못했다. 그런 나에게 처음으로 글을 읽는 재미를 알려준 소설이 있었으니 바로 지금은 고인이 되신 이청준 작가님의 "눈길" 이라는 소설이다.

왜 이렇게 재밌게 읽었나? 생각을 해보면
일단 소설이 짧아서 읽기 쉬웠고
그리고, 너무 슬펐다. 그냥 너무 슬펐다.
본 소설의 주요 작중 화자는 아들과 어머니 이다. 이들의 집안은 과거 풍비박산 났었고, 어머니는 엄동설한에 눈길을 따라 급하게 아들을 다른 지역으로 떠나 보내야만 했다. 아들은 평생 동안 자신이 버림 받았다고 생각했다. 아들에게 있어 눈길은 그런 곳이 었다. 하지만, 어머니는 자식을 버린 적이 없다. 어머니도 돌아갈 곳이 없었다. 단지, 아들을 떠나 보낸 눈길을 홀로 걸어가며 아들의 안녕을 기원 했을 뿐.
"길을 혼자 돌아가시던 그대 일을 말씀이세요?"
"눈길을 혼자 돌아가다 보니 그 길엔 아직도 우리 둘 말고는 아무도 지나간 사람이 없지 않았겄냐. 눈발이 그친 신작로 눈 위에 저하고 나하고 둘이 걸어온 발자국만 나란히 이어져 있구나."
"그래서 어머님은 그 발자국 때문에 아들 생각이 더 간절하셨겠네요."
"간절하다뿐이었겄냐. 신작로를 지나고 산길을 들어서도 굽이굽이 돌아온 그 몹쓸 발자국들에 아직도 도란도란 저 아그의 목소리나 따뜻한 온기가 남아 있는 듯만 싶었제. 산비둘기만 푸르륵 날아올라도 저 아그 넋이 새가 되어 다시 되돌아오는 듯 놀라지고, 나무들이 눈을 쓰고 서 있는 것만 보아도 뒤에서 금세 저 아그 모습이 뛰어나올 것만 싶었지야. 하다 보니 나는 굽이굽이 외지기만 한 그 산길을 저 아그 발자국만 따라 밟고 왔더니라. 내 자석아, 내 자석아, 너하고 둘이 온 길을 이제는 이 몹쓸 늙은 것 혼자서 너를 보내고 돌아가고 있구나!"
"어머님 그때 우시지 않았어요?"
"울기만 했겄냐. 오목오목 디뎌 논 그 아그 발자국마다 한도 없는 눈물을 뿌리며 돌아왔제. 내 자석아, 내 자석아 ,부디 몸이나 성히 지내거라. 부디부디 너라도 좋은 운 타서 복 받고 살거라… 눈앞이 가리도록 눈물을 떨구면서 눈물로 저 아그 앞길만 빌고 왔제…>"
노인의 이야기는 이제 거의 끝이 나 가고 있는 것 같았다. 아내는 이제 할 말을 잊은 듯 입을 조용히 다물고 있었다.
"그런디 그 서두를 것도 없는 길이라 그렁저렁 시름없이 걸어온 발걸음이 그래도 어느 참에 동네 뒷산을 당도해 있었구나. 하지만 나는 그 길로는 차마 동네를 바로 들어설 수가 없어 잿등 위에 눈을 쓸고 아직도 한참이나 시간을 기다리고 앉아 있었더니라…."
"어머님도 이젠 돌아가실 거처가 없으셨던 거지요."


눈길은 차가웠지만, 아들에 대한 어머니의 마음 만큼은 그 모든 눈을 녹여버릴 만큼 따뜻했다. 그 마음이 따뜻해서일까, 아니면 그 마음을 몰라주는 아들이 안타까워서일까. 이 소설을 보면서 몇 번이고 나도 울었는지 모른다 ㅜㅜ 지금도 슬픔 ㅜㅜ 그래서 중2병이 도질때마다 가끔 이 소설을 읽는다.
이번 글에서는 간단한 데이터 분석을 통해 故 이청준 작가님의 눈길을 다시 살펴보려 한다.
1. 데이터 전처리
슬픈건 슬픈거고 전처리는 전처리대로 해야 한다.


우선, 데이터를 살펴보자.

최초의 파일 형식은 hwp 파일이다. olefile, pyhwp등 라이브러리를 이용하여 hwp 파일을 파싱해보려 했으나, body 부분에서 decoding error가 계속 발생하여 그냥, txt 파일을 줄별로 읽어 들이기로 했다. 이미지에서 보면 알겠지만, txt 파일로 단순히 변환해도 문장들이 줄별로 아름답게 정렬된다. 역시 소설은 소설인가.
import pandas as pd
file = open('C:/Users/HOME/Dropbox/git/pubJupyter/sideProject/snowRoad.txt')
txtLines = file.readlines()
#원본
df_original = pd.DataFrame()
df_original['line'] = txtLines
#원본은 남겨둠
data = df_original.copy()
data['original_line'] = data['line'] #혹시 몰라서 남겨둠readlines로 text 파일을 줄별로 읽어왔다. 이후, 데이터 프레임으로 바꿔준 후 혹시 몰라 original 데이터 프레임을 남겨 두었다.
1-1. 띄어쓰기 라인 제거

문장 단위로 데이터가 잘 들어간 것 같다. 여기서, 엄밀히 구분하자면, 한 행에 들어가 있는 line 컬럼은 단일 문장 + 복합 문장일 수 있다. 문단과 단락의 차이인 것 같은데, 문단이 들어가 있다고 생각하면 될 것 같다. 화자가 한 호흡에 내뱉는 대사. 영어에서는 문단과 단락을 모두 paragraph로 사용한다.
#띄어쓰기 라인표시 제거
data['line'] = data['line'].str.replace('\n', '')다음으로 띄어쓰기 라인표시 \n을 제거해주고

1-2. 빈열 제거 및 단락구분자 추가
#빈 열 제거, 빠진 열이 있으니 인덱스도 리셋
data = data.loc[(data['line'] != '')].reset_index(drop=True)비어있는 열도 제거해준다. 이후 index를 다시 reset 해준다.
#단락 구분자 확인 - 숫자로 시작하는 부분만 구분하기 위해 ^ 메타문자 추가
data.loc[data['line'].str.contains(r"^\d{1}")]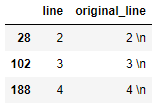
위와 같은 숫자로 단락이 구분되어 있다. 해당 인덱스를 이용하여 단락구분자를 추가해보자.
#단락구분자 추가
data['paragraph'] = 1
data.at[28:102, 'paragraph'] = 2
data.at[102:188, 'paragraph'] = 3
data.at[188:, 'paragraph'] = 4
경계선인 index 28행을 기준으로 단락이 잘 구분된 것을 알 수 있다. 마무리로, 단락 구분자를 제거해주자.
#숫자만 있는 열 제거
data = data.loc[~data['line'].str.contains(r"\d{1}")].reset_index(drop=True)
1-3. 간접인용, 직접인용 구분자 추가
#간접인용과 직접인용 구분
data[data['line'].str.contains(r"(\".*\")|(“.*”)")]
아주 감사하게도, ""로 직접인용이 표시되어 있다. ""만으로 “”는 인식이 안되어 따로 구분자를 추가했다.
data['quote'] = '간접인용'
data.loc[data['line'].str.contains(r"(\".*\")|(“.*”)"), 'quote'] = '직접인용'이를 이용하여 간접인용과 직접인용으로 구분한다.
#문장 속의 인용 부호 및 마침표를 제거해준다.
data['line'] = data['line'].str.replace(r"[^가-힣\s]", '')
#제목과 저자 행 제거
data = data.iloc[2:, ].reset_index(drop = True)
data.head()마지막으로, 문장 속의 인용 부호 및 마침표와 제목/저자 행을 제거해준다.

위와 같이 대략적인 전처리가 완료되었다. 언어학적으로 정확히 맞는 건지는 모르겠다만, 직접인용은 일종의 대사로 간접인용은 독백으로 생각하면 된다.
예를 들어, "내일 아침 올라가야겠어요"는 진행되는 대화 내용중 일부이다. 반면, 노인과 아내가 동시에 밥숟가락을 멈추며 나의 얼굴을 멀거니 건너다본다 는 3인칭 시점에서 주인공이 현재 상황에 대해 해설을 한 것이다. 여기서, 독백은 오로지 주인공(=아들)만 한다.
2. 분석
2-1. 문단 수 및 평균 길이
print(data.paragraph.value_counts().sort_index())
>> 1 26
>> 2 68
>> 3 82
>> 4 56서론인 1단락의 문단수가 가장 적은 것을 알 수 있다. 다음으로, 단락별 문단 평균 길이를 살펴 보자.
#문장 길이 확인
data['len'] = data['line'].map(lambda x : len(x))
data.groupby('paragraph')['len'].agg(['mean', 'median'])

뒷 단락으로 갈수록 평균 문단 길이가 길어지고 있다. 즉, 점점 한 문단의 호흡이 길어지고 있다는 것을 알 수 있다. 특히, 4단락의 경우 평균이 중앙값보다 한참 큰데, 오른쪽으로 꼬리가 긴 분포를 예상해 볼 수 있다. 즉, 유난히 길이가 긴 몇개의 문단이 전체 평균을 왜곡했다고도 볼 수 있다. 다른 한편으로는, 인물들이 주고 받는 대화 양상에 어떤 변화가 생겼다고도 생각해볼 수 있을 것 같다.
2-2. 워드카운팅
#형태소 분리 Kkma
from konlpy.tag import Kkma
kkma = Kkma()
#최종데이터프레임
data_text = data.copy()
data_text['tag_list'] = data_text['line'].map(lambda x : kkma.pos(x))
꼬꼬마 형태소 분리기를 이용하여 문장에서 품사별로 단어를 분리했다. 불용어 처리를 따로 하지 않았기 때문에 명사 품사만(일반명사, 고유명사) 따로 뽑아내었다.
from collections import defaultdict
def get_morphos_by_tags(tag_list: list, s: str) -> list:
d = defaultdict(list)
# 품사가 튜플의 오른쪽에 위치하므로 value, key 순으로 배열
for value, key in s:
d[key].append(value)
temp_list = []
# 키 값에 해당하는 단어들을 temp_list에 extend
for key_value in list(d.keys()):
if key_value in tag_list:
temp_list.extend(d[key_value])
return temp_list
tags = ['NNG', 'NNP']
data_text['ExtractTags'] = data_text['tag_list'].map(lambda x: get_morphos_by_tags(tags, x))
ExtractTags열에 명사 품사만 따로 분리된 것을 확인할 수 있다. (처음에는 pykomoran의 get_morphes_by_tags 메서드를 사용하려 했으나, 이상하게 어느 문단은 처리가 되고, 어느 문단은 처리가 되지 않았다.)
#minus 표시 안되는 오류 해결
import matplotlib
matplotlib.rcParams['axes.unicode_minus'] = False
#한글 표시 오류 해결
import matplotlib.pyplot as plt
from matplotlib import font_manager, rc
font_path = "C:/Windows/Fonts/NanumGothic.ttf"
font = font_manager.FontProperties(fname=font_path, size=20).get_name()
rc('font', family=font)
#워드 카운트
plt.figure(figsize=(10, 5))
data_text.explode('ExtractTags')['ExtractTags'].value_counts().sort_values(ascending=False).head(20).plot.bar();워드카운팅을 할 때, 약간의 꼼수를 사용했다. 보통은 dict 타입 변수를 선언하고 unique 값이 생길때마다 그 값을 key로 추가하고 같은 값이 나오면 카운트를 +1씩 증가시킨다. get_morphos_by_tags 의 결과가 list 타입이기 때문에 여기서는 expand 메서드를 활용했다.
EXPAND METHOD 예시
[1, 2, 3]
>> 1
>> 2
>> 3
expand 메서드를 사용하면 위와 같이 wide 폼을 long 폼으로 변환할 수 있다. 이후, series 타입에서 간단하게 value_counts를 적용할 수 있었다.

소설 전체를 통틀어 가장 많이 나온 단어는 "노인"이다.
왜 가장 많이 등장한 것일까?
data_text.loc[(data_text.line.str.contains(r"노인")), ["line", "quote"]]
소설에서 주요 인물은 아내/어머니/아들(남편) 세 명이다. 그리고, 앞서 말했듯이 간접인용에 등장하는 인물을 아들 밖에 없다. 따라서, 노인은 아들의 어머니라고 할 수 있다.
data_text.loc[(data_text.line.str.contains(r"노인"))&(data_text.quote != "간접인용"), ["line", "quote"]]
그리고, 직접인용 문구 중에 유일하게 "노인"이 등장하는 문단은 한 문단 밖에 없다. 이마저도 아내가 남편을 나무라는 상황에서 나온다. 따라서, 노인이라는 단어는 작중에서 아들이 노모를 일컫는 말이며, 이 단어를 통해 노모에 대한 아들의 심적 거리감을 알 수 있다. 아들은 엄마한테 버림받았다(=엄마가 돌봐주지 않음, 타지로 자식을 떠나보냄)고 생각하고 이로 인한 원망이 "노인"이라는 단어를 통해서 표출 된 것으로 볼 수 있다.
2-3. 발화 구조
앞서 보았듯이, 본 소설에서 가장 많이 등장한 단어는 "노인"이라고 할 수 있다. 그렇다면, 노인이라는 단어는 몇 문단마다 한 번씩 등장할까?

NLTK의 Dispersion Plot과 비슷한 뷰를 구현하기 위해 약간의 꼼수를 사용했다.
data_text['interval'] = '노인X'
data_text.loc[(data_text['line'].str.contains(r"노인")), "interval"] = '노인O'
data_text['interval_value'] = 1우선, "노인"이라는 단어가 등장하는 문단과 그렇지 않은 문단을 구분하고 전체 값이 모두 1인 interval_value라는 컬럼을 추가했다. 본 데이터 프레임의 index가 문단 진행 순서대로 이루어져 있다는 것을 감안 했을 때, index를 x축으로 사용하면 dispersion plot과 비슷한 뷰를 구현할 수 있을 것이다.
plt.figure(figsize=(10, 3))
plt.title("노인 단어 등장 간격(문단간)")
sns.scatterplot(data=data_text, x=data_text.index.values, y='interval_value', hue='interval', marker="|");
중간 중간 호흡이 끊어지는 부분도 있지만, 첫 문단 부터 마지막 문단까지 "노인"이라는 단어는 아주 고르게 그리고 꾸준히 나오고 있다. 즉, 소설이 끝나는 그 순간 까지도 아들은 어머니를 "노인"이라고 칭하고 있다.
plt.figure(figsize=(10, 3))
plt.title("간접 인용 등장 간격(문단간)")
sns.scatterplot(data=data_text, x=data_text.index.values, y='interval_value', hue='quote', alpha=0.7, marker="|");
마찬가지로 간접 인용 등장 간격을 보자.
data_text.groupby("quote").size()
>> 간접인용 142
>> 직접인용 90직접인용보다 더 잦은 빈도로 등장하고 있다. 즉, 소설 속의 인물은 아내/아들(남편)/어머니 세 명인데, 누구 한명이 말을 하면 그 말에 대해서 독백 형태로 아들이 해설을 하고 있다는 것을 알 수 있다(빅마우스?)
2-4. 단락별 분석
fig, axes = plt.subplots(nrows=2, ncols=2, figsize=(10, 7))
data_text[(data_text['paragraph'] == 1)].explode('ExtractTags')['ExtractTags'].\
value_counts().sort_values(ascending=False).head(20).plot.bar(ax=axes[0, 0])
data_text[(data_text['paragraph'] == 2)].explode('ExtractTags')['ExtractTags'].\
value_counts().sort_values(ascending=False).head(20).plot.bar(ax=axes[0, 1])
data_text[(data_text['paragraph'] == 3)].explode('ExtractTags')['ExtractTags'].\
value_counts().sort_values(ascending=False).head(20).plot.bar(ax=axes[1, 0])
data_text[(data_text['paragraph'] == 4)].explode('ExtractTags')['ExtractTags'].\
value_counts().sort_values(ascending=False).head(20).plot.bar(ax=axes[1, 1])
axes[0, 0].set_title("단락1")
axes[0, 1].set_title("단락2")
axes[1, 0].set_title("단락3")
axes[1, 1].set_title("단락4")
axes[0, 0].set_ylim(0, 65)
axes[0, 1].set_ylim(0, 65)
axes[1, 0].set_ylim(0, 65)
axes[1, 1].set_ylim(0, 65)
plt.tight_layout();
단락별로 나무어 워드 카운트를 살펴 보았다. 2단락에서는 "빚"이라는 단어가 등장한다.
data_text.loc[(data_text['line'].str.contains(r"빚")), 'line'].head()
주인공이 과거 어떤 상황에 처했었는지 알 수 있다. 또한, 다른 한편으로는 어머니를 안좋게 생각하는 것에 대한 일종의 죄책감도 같이 드러난다고 할 수 있다.
단락3 에서는 아내, 어머님이라는 단어가 등장한다.
data_text.loc[(data_text['line'].str.contains(r"어머님")), 'line'].head()
아내가 "노인"을 "어머님"이라고 부르며, 대화를 이끌어내고 있는 것을 알 수 있다.
그리고, 마지막 단락4에서 드디어 눈과 길 본 소설의 제목에 해당하는 단어가 등장한다.
data_text.loc[(data_text.index == 219)&(data_text['line'].str.contains(r"눈"))&(data_text.paragraph == 4), 'line'].values
예시 문장에서, 자식에 대한 부모님의 진심어린 마음이 드러나는 것을 알 수 있다. 다만, 형태소 분류 결과로 봐서 "눈물"을 "눈"과 "물" 두 단어로 분리한 것 같다.
2-5. 발화자별 분석
본 소설의 발화자들을 구분하여 분석해보려 한다.
cond_narrator1 = (data_text.quote == '직접인용')
cond_narrator2 = (data_text['original_line'].str.contains(r"([요오까][\.\?])|([니시]다\.)"))
cond_narrator3 = (data_text['original_line'].str.contains(r"(어머님)|(어머니)|(당신)|(여보)"))
data_text['narrator'] = 'base'
data_text.loc[(cond_narrator1)&(~cond_narrator2), 'narrator'] = '직접인용_노인'
data_text.loc[(cond_narrator1)&(cond_narrator2)&(cond_narrator3), 'narrator'] = '직접인용_부인'
data_text.loc[(cond_narrator1)&(cond_narrator2)&(~cond_narrator3), 'narrator'] = '직접인용_아들'
data_text.loc[(data_text.quote == '간접인용'), 'narrator'] = '간접인용_아들'본 소설에서 간접인용을 하는 사람은 아들 밖에 없다는 점 그리고, 반말을 하는 사람은 어머니 밖에 없다는 점 + 어머님이라고 부르는 사람도 아내 밖에 없다는 점을 이용해 발화자들을 구분해 보았다.
len_narrator = data_text.groupby(['narrator', 'paragraph'])['len'].mean().reset_index()
sns.lineplot(data=len_narrator, x='paragraph', y='len', hue='narrator')
소설이 진행될수록 노인의 문단은 점점 더 길어지고 부인과 아들의 대사는 점점 짧아진다. 즉, 문단 뒤로 갈수록 노인의 심정이 그만큼 잘 드러난다고 볼 수 있다.
fig, axes = plt.subplots(nrows=2, ncols=2, figsize=(10, 7))
data_text[(data_text['paragraph'] == 1)&(data_text['narrator'] == '직접인용_노인')].explode('ExtractTags')['ExtractTags'].\
value_counts().sort_values(ascending=False).head(20).plot.bar(ax=axes[0, 0])
data_text[(data_text['paragraph'] == 2)&(data_text['narrator'] == '직접인용_노인')].explode('ExtractTags')['ExtractTags'].\
value_counts().sort_values(ascending=False).head(20).plot.bar(ax=axes[0, 1])
data_text[(data_text['paragraph'] == 3)&(data_text['narrator'] == '직접인용_노인')].explode('ExtractTags')['ExtractTags'].\
value_counts().sort_values(ascending=False).head(20).plot.bar(ax=axes[1, 0])
data_text[(data_text['paragraph'] == 4)&(data_text['narrator'] == '직접인용_노인')].explode('ExtractTags')['ExtractTags'].\
value_counts().sort_values(ascending=False).head(20).plot.bar(ax=axes[1, 1])
axes[0, 0].set_title("직접인용노인_단락1")
axes[0, 1].set_title("직접인용노인_단락2")
axes[1, 0].set_title("직접인용노인_단락3")
axes[1, 1].set_title("직접인용노인_단락4")
axes[0, 0].set_ylim(0, 65)
axes[0, 1].set_ylim(0, 65)
axes[1, 0].set_ylim(0, 65)
axes[1, 1].set_ylim(0, 65)
plt.tight_layout();
노인은 주로 "집"에 대해서 얘기하고 마지막 단락에서 눈과 길, 그리고 차부에 대해서 얘기하는 것을 알 수 있다.

차부는 과거 터미널을 일컫는 말로 인근 슈퍼에서 버스 티켓을 팔고는 했었다.
fig, axes = plt.subplots(nrows=2, ncols=2, figsize=(10, 7))
data_text[(data_text['paragraph'] == 2)&(data_text['narrator'] == '직접인용_부인')].explode('ExtractTags')['ExtractTags'].\
value_counts().sort_values(ascending=False).head(20).plot.bar(ax=axes[0, 1])
data_text[(data_text['paragraph'] == 3)&(data_text['narrator'] == '직접인용_부인')].explode('ExtractTags')['ExtractTags'].\
value_counts().sort_values(ascending=False).head(20).plot.bar(ax=axes[1, 0])
data_text[(data_text['paragraph'] == 4)&(data_text['narrator'] == '직접인용_부인')].explode('ExtractTags')['ExtractTags'].\
value_counts().sort_values(ascending=False).head(20).plot.bar(ax=axes[1, 1])
axes[0, 0].set_title("직접인용부인_단락1")
axes[0, 1].set_title("직접인용부인_단락2")
axes[1, 0].set_title("직접인용부인_단락3")
axes[1, 1].set_title("직접인용부인_단락4")
axes[0, 0].set_ylim(0, 65)
axes[0, 1].set_ylim(0, 65)
axes[1, 0].set_ylim(0, 65)
axes[1, 1].set_ylim(0, 65)
plt.tight_layout();
그리고, 부인이 어머님/말씀 등의 단어를 사용하며 어머니의 얘기를 들어주고 한번 더 해석해주는 것을 알 수 있다.
3. 마치며
지금까지, 간단한 텍스트 분석을 통해 故이청준 작가님의 눈길이라는 소설을 살펴 봤다. 나는 이 소설을 10번도 넓게 읽어봐서 사실 다소 도메인 지식?에 의지하여 분석을 한 측면이 없지 않아 있다. 하지만, 내가 제일 좋아하는 소설을 내가 좋아하는 데이터 분석을 통해 다시 살펴볼 수 있어서 재밌었다.
'딥상어동의 딥한 데이터 분석' 카테고리의 다른 글
| [Python] google maps API 가격 정책과 사용법 (0) | 2022.09.18 |
|---|---|
| [데이터로 보는 주식] 물타기 도대체 언제 할것이냐, 그것이 문제로다. (2) | 2021.12.05 |
제 블로그에 와주셔서 감사합니다! 다들 오늘 하루도 좋은 일 있으시길~~
포스팅이 좋았다면 "좋아요❤️" 또는 "구독👍🏻" 해주세요!
![[Python] google maps API 가격 정책과 사용법](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FbY9vik%2FbtrMkuItB5h%2FE5PzmN5c59cxVR9R5pkYL1%2Fimg.png)
![[데이터로 보는 주식] 물타기 도대체 언제 할것이냐, 그것이 문제로다.](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FcwSURB%2FbtrmZH6deg6%2FatvH4xsdsuoaPKxFMiL0f0%2Fimg.png)