![[ubuntu] Mysql 원격 접속 허용후 Python(pd.to_sql)과 연동해보기](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FNQlqr%2FbtrDXbh3yX1%2FAAAAAAAAAAAAAAAAAAAAAFqWmMsGjUX4vnDaVp7VLUTOZnjz29e4ZR8znxOfpyqG%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1764514799%26allow_ip%3D%26allow_referer%3D%26signature%3D97sBqPZfK1FohDwr%252FPqm00YGlsc%253D)


핵심 내용
ubuntu에서 MySQL Server 원격 접속 허용 후, Python과 연동하는 과정을 다룹니다. 본 글은 아래의 내용들을 포함합니다.
1. ubuntu MySQL설치법
2. MySQL 원격 접속 허용하는 방법
3. Workbench 연결방법
4. Python mysql.connector 사용법
5. pandas의 to_sql메서드를 이용하여 pandas 데이터프레임을 mysql로 적재하기
ubuntu MySQL설치하기
ubuntu 버젼은 20.04이며 GCP를 이용했습니다. VM Instance를 생성하는 방법은 아래 글을 참고 부탁드립니다.
https://gibles-deepmind.tistory.com/116?category=954919
[GCP] VM Instance 생성하기
1. 무료로 시작하기 무료로 시작하기를 클릭해준다. 적당한 걸 클릭해주고 계좌 유형은 귀찮으니, 개인을 선택해준다. 그리고, 이름 및 주소를 적당히 입력. 참고로 우편번호는 시/군/구에 맞게
gibles-deepmind.tistory.com
기존 패키지들의 최신버젼이 있는지 확인하고(update) upgrade합니다.
sudo apt-get update
sudo apt-get upgrade
그런 다음, mysql-server를 설치해줍니다. ubuntu 20.04버젼인 경우 mysql 8버젼이 설치됩니다.
sudo apt-get install mysql-server -y
여기서 잠깐! 하나 주의하셔야 할 부분이 있습니다. 우분투 버젼이 18.04인 경우, mysql-server로 설치 시 설치 버젼이 다를 수 있다는 점인데요. 18.04버젼인 경우 Mysql8을 설치하기 위해 MySQL APT Repository를 이용해야 합니다. 관련된 내용은 아래 글에서 참조하실 수 있습니다. 저는 우분투를 20.04 버젼으로 구성하였기 때문에 추가적인 조치를 하지는 않았습니다.
https://www.sqlshack.com/how-to-install-mysql-on-ubuntu-18-04/
How to install MySQL on Ubuntu
In this article, it will be shown how to install MySQL 5.7 and 8.0.19 versions on an Ubuntu 18.04 machine.
www.sqlshack.com
아래 명령어를 실행해줍니다.
sudo service mysql status
active! 라는 문구가 나오면 정상입니다!
버젼도 한번 확인해줍니다. 8버젼으로 잘 설치되었네요.
mysql --version
sudo service mysql 명령어는 아래와 같이 활용 가능합니다.
sudo service mysql start
sudo service mysql stop
sudo service mysql restart
sudo service mysql status
여기까지 하시면 mysql설치는 완료됩니다.
MySQL 원격접속 허용방법
원격 접속을 허용하기 위해서는 몇 가지 조치를 취해야 합니다.
1. 허용 ip주소 범위 변경
2. 계정 접근 권한 및 ip 허용 범위 설정
허용 ip 주소 범위 변경
mysqld.cnf파일을 수정할 것입니다. sudo명령어를 사용하지 않으면 파일 수정이 되지 않는 경우도 있기 때문에 같이 사용해줍니다.
sudo nano /etc/mysql/mysql.conf.d/mysqld.cnf
여기서 아래와 같이 bind-address와 mysqlx-bind-address를 모두 0.0.0.0으로 수정해줍니다.

0.0.0.0으로 설정하는 이유는 어디서든 접근이 가능하게 하도록 하기 위해서입니다. 좀 더 자세한 내용이 궁금하신 분은 아래 글을 참고해보시면 좋을 것 같습니다.
https://rootable.tistory.com/447
0.0.0.0 의 의미
나는 HackCTF의 LOL 문제(https://rootable.tistory.com/entry/HackCTF-LOL)를 풀고 정확히 0.0.0.0이 무엇을 의미하는지 찾아보았다. 기존에 내가 알고 있던 0.0.0.0의 의미는 '모든 IP를 의미한다' 정도로만 알..
rootable.tistory.com
여기까지 하고 mysql 서버를 재시작 해줍니다.
sudo service mysql restart
계정 접근 권한 설정
우선, mysql 환경으로 접속합니다.
sudo mysql -u root저는 airflow테스트DB와 테스트DB에 접속하기 위한 계정을 따로 만들어줄 예정입니다. 먼저 test_db를 생성해줍니다.
CREATE DATABASE airflow_test_db;다음으로, 접속 계정도 따로 생성해줍니다.
CREATE USER 'test'@'%' IDENTIFIED BY '비밀번호'
여기서 %는 모든 IP를 의미합니다. %자리에 아래와 같이 구체적인 주소도 할당할 수 있는데요.

자세한 내용은 아래 글을 참조하시면 좋을 것 같습니다.
https://www.cyberciti.biz/faq/how-to-create-mysql-admin-user-superuser-account/
How to create MySQL admin user (superuser) account
Explains how to create a new admin (superuser) user in MySQL and make it an admin user with root-like access to the databases.
www.cyberciti.biz
저희는 언제 어디서 mysql서버로 접속할지 모르니 %표시로 계정을 생성해줍니다.
다음으로, airflow_test_db에 대해 계정이 모든 권한을 가질 수 있도록 설정해줍니다.
GRANT ALL PRIVILEGES ON airflow_test_db.* TO '테스트계정'@'%' WITH GRANT OPTION;그리고, 아래 명령어를 실행해줍니다.
FLUSH PRIVILEGES;mysql환경설정 변경 후 재시작 없이 변경한 설정을 재적용하는 부분입니다. 아래 글에서 자세한 내용을 참고하실 수 있습니다.
https://m.blog.naver.com/zzang9ha/222009521090
MySQL(MariaDB) - flush privileges
안녕하세요~ 보통 DB에서 MySQL(MariaDB)의 환경 설정을 변경할 경우, 아래와 같은 명령어를 입력...
blog.naver.com
여기까지 작성 후 확인해봅시다. DB도 정상적으로 생성되었고, 계정도 %(모든IP접근 허용)로 잘 생성됐네요.
show databases;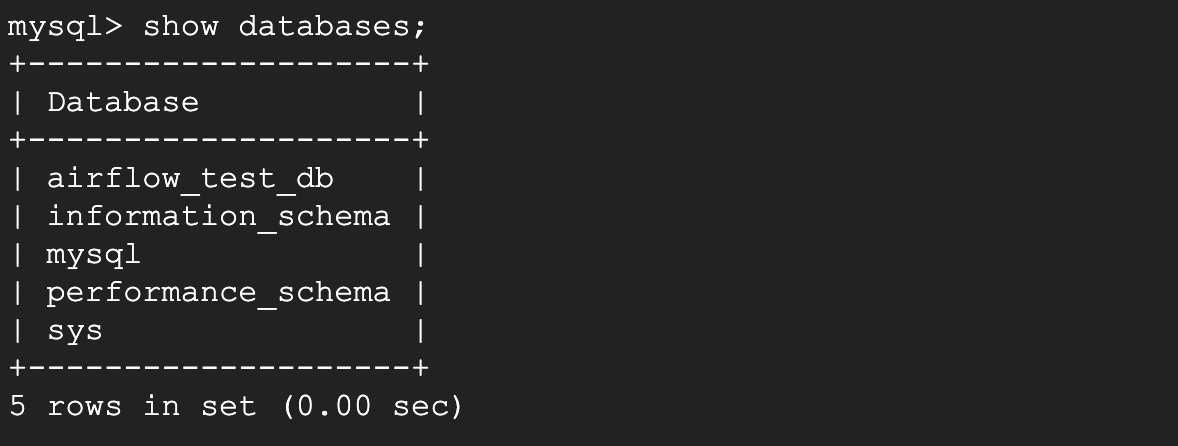
use mysql;
select user, host from user;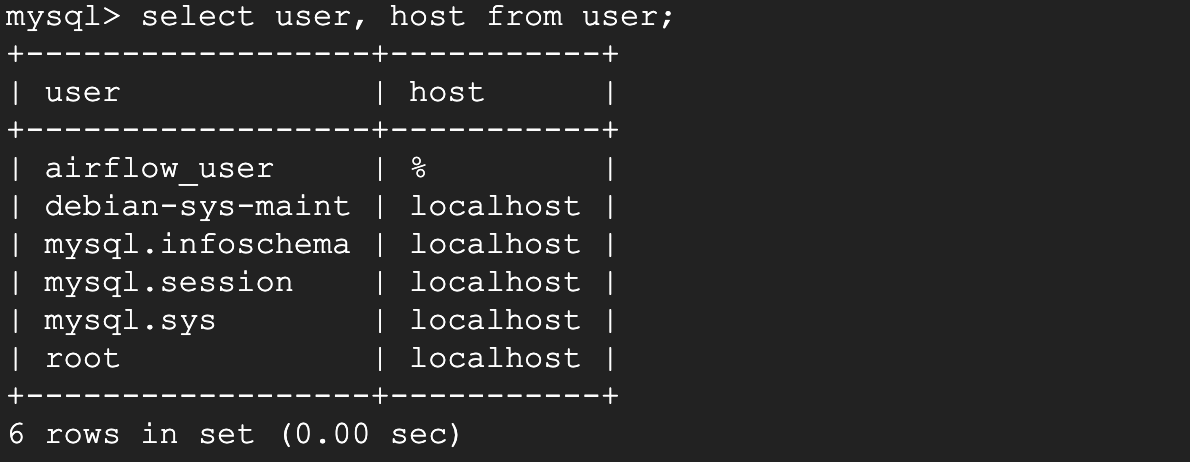
여기까지 하시고 quit명령어를 이용해 밖으로 나와줍니다.
Workbench 연결 방법
MySQL Workbench는 아래 사이트에서 다운 받으실 수 있습니다.
https://dev.mysql.com/downloads/workbench/
MySQL :: Download MySQL Workbench
Select Operating System: Select Operating System… Microsoft Windows Ubuntu Linux Red Hat Enterprise Linux / Oracle Linux Fedora macOS Source Code Select OS Version: All Windows (x86, 64-bit) Recommended Download: Other Downloads: Windows (x86, 64-bit), M
dev.mysql.com
Select Operating System에서 운영체제를 선택하시고 Download버튼을 클릭해줍니다. Archives를 누르면 버전을 선택해서 다운받을 수 있습니다.
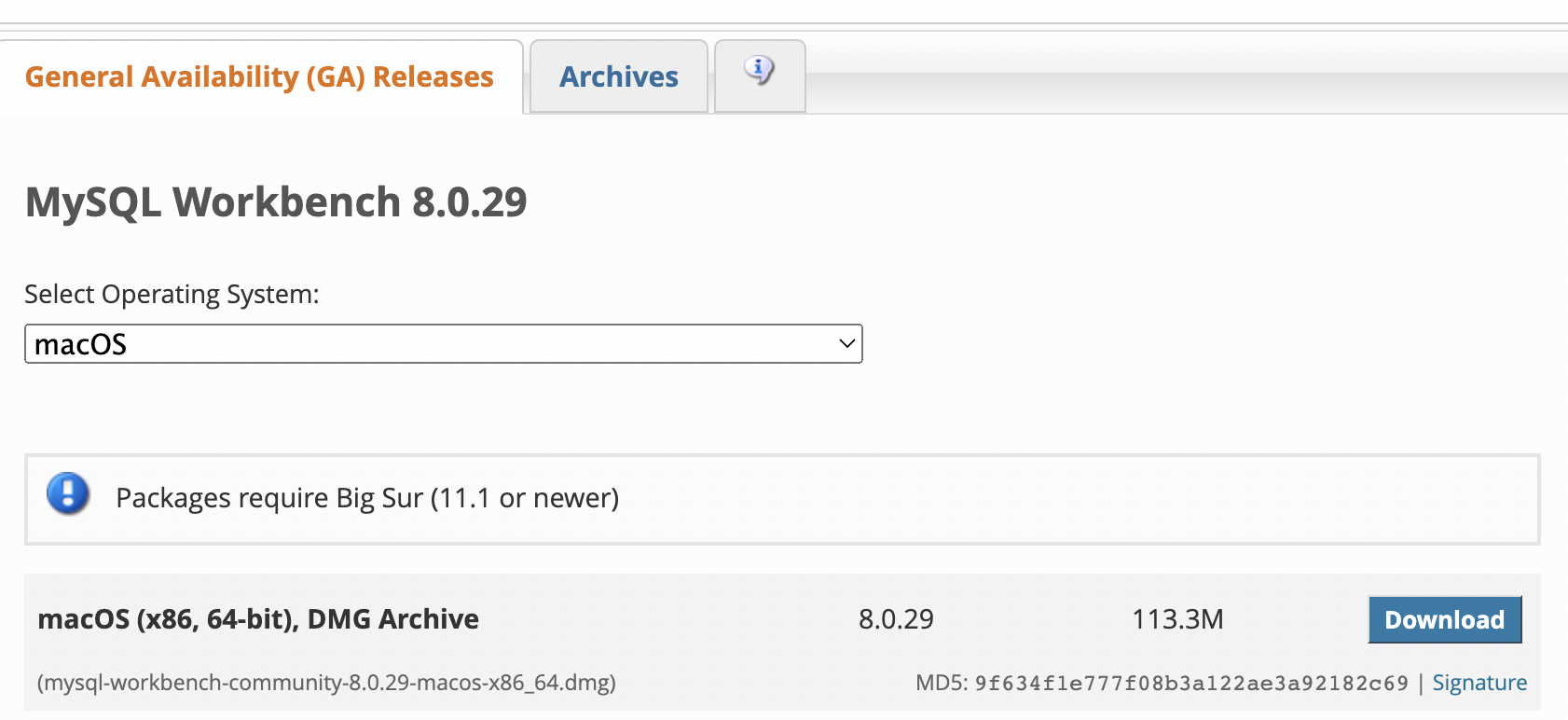
다운로드 및 설치 완료후(설치는 파일만 클릭해주면 됩니다.) MySQL Workbench를 실행하면 아래와 같은 화면을 보실 수 있는데요.
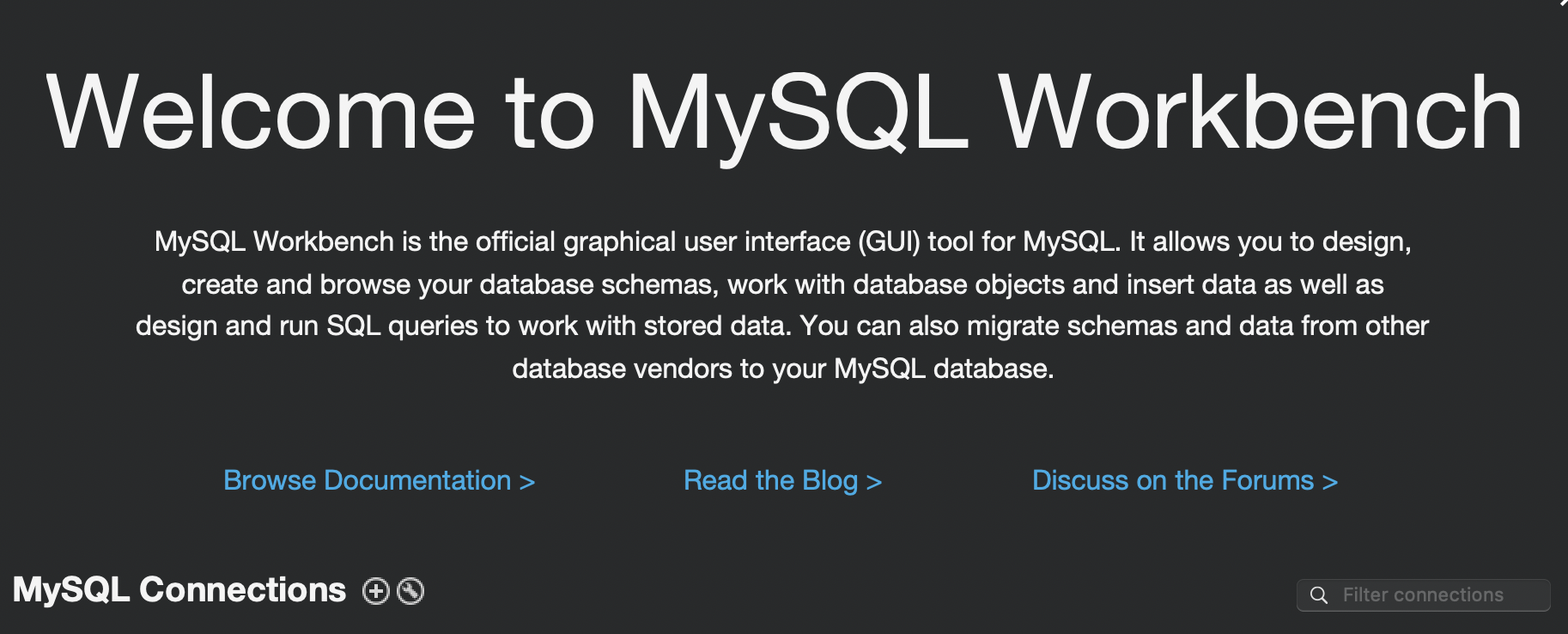
여기서 +버튼을 눌러줍시다. 그럼 아래와 같은 화면을 볼 수 있는데요.
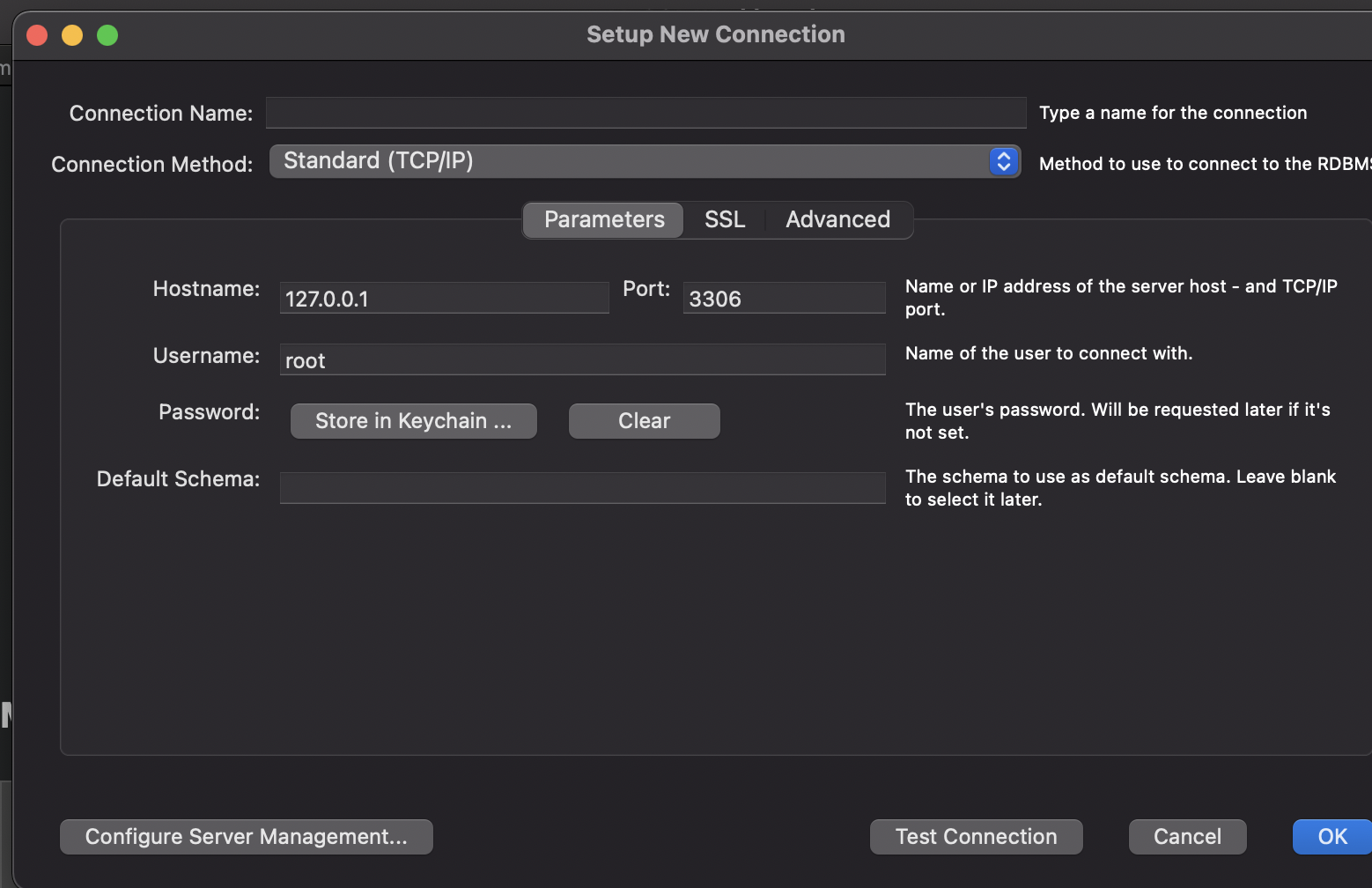
딱 아래의 것들만 수정해주면 됩니다.
Connection Name: 연결 이름 설정, 자유롭게 작성
Hostname: GCP의 외부IP입력
Username: 앞서 생성한 계정 이름 입력
Password: Store in Keychain 클릭 후 앞서 생성한 계정의 비밀번호 입력
그리고, 정상적으로 연동되면 아래와 같은 화면을 볼 수 있습니다.
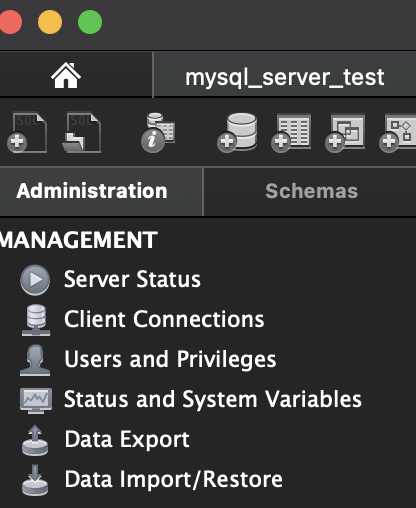
여기까지 완료되면 원격접속 이상무 입니다!
Python MySQL Connector 사용법
MySQL Connect설치는 아래 공홈 가이드를 참조했습니다.
https://dev.mysql.com/doc/connector-python/en/connector-python-installation-binary.html
MySQL :: MySQL Connector/Python Developer Guide :: 4.2 Installing Connector/Python from a Binary Distribution
4.2 Installing Connector/Python from a Binary Distribution Connector/Python installers in native package formats are available for Windows and for Unix and Unix-like systems: Windows: MSI installer package Linux: Yum repository for EL7 and EL8 and Fedora;
dev.mysql.com

8.0이나 5.7/5.6 버젼 사용을 권장한다는 내용도 있네요. 참고하시면 좋을 것 같습니다.
아래 명령어로 mysql-connector-python을 설치해줍니다.
pip install mysql-connector-python
연동 가이드는 아래 문서를 참고했습니다.
https://dev.mysql.com/doc/connector-python/en/connector-python-example-connecting.html
MySQL :: MySQL Connector/Python Developer Guide :: 5.1 Connecting to MySQL Using Connector/Python
5.1 Connecting to MySQL Using Connector/Python The connect() constructor creates a connection to the MySQL server and returns a MySQLConnection object. The following example shows how to connect to the MySQL server: import mysql.connector cnx = mysql.conn
dev.mysql.com
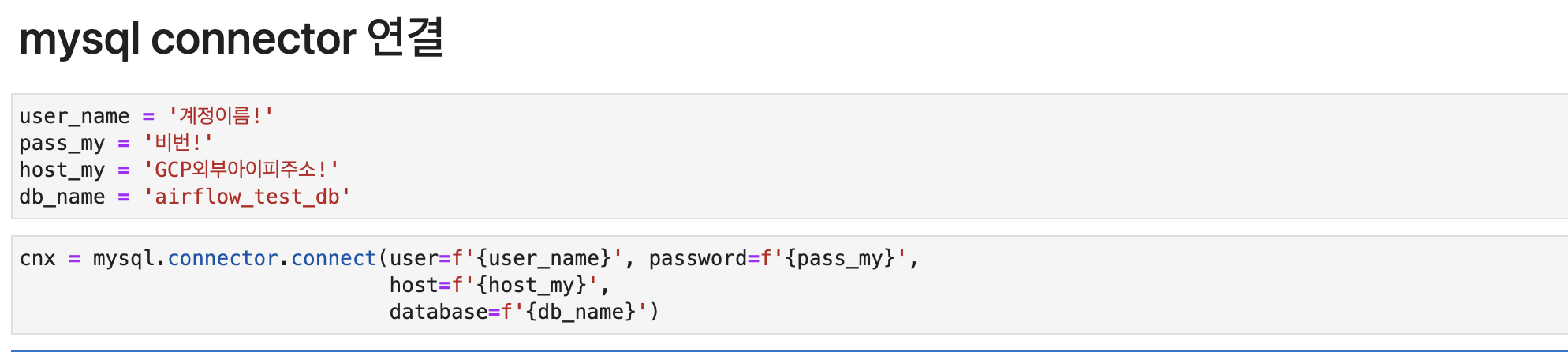
아래와 같이 입력해주기만 하면 됩니다!
import mysql.connector
user_name = '계정이름!'
pass_my = '비번!'
host_my = 'GCP외부아이피주소!'
db_name = 'airflow_test_db'
cnx = mysql.connector.connect(user=f'{user_name}', password=f'{pass_my}',
host=f'{host_my}',
database=f'{db_name}')
별 에러 없이 실행된다면 잘 연동 된겁니다!
이외에 공홈에 다양한 가이드들이 있으니, 한번 살펴보시면 좋을 것 같습니다.

pd.to_sql을 이용하여 데이터프레임 DB에 적제하기
그런데, mysql.connector로 데이터 프레임 전체를 DB로 적재하는 과정은 꽤나 귀찮았습니다. 보통 for문으로 row하나 하나 insert하던데 속도는 둘째 치고 코드를 작성하는 과정이 문득 귀찮게 느껴졌습니다. 그래서 좀 더 찾아보니 pandas내에 to_sql이라는 메서드가 있더라구요!
여기서 잠깐! to_sql을 사용하기 위해서는 sqlalchemy를 설치해야합니다. anaconda에는 기본적으로 설치되어 있습니다.
import sqlalchemy
왜냐하면, to_sql메서드가 sqlalchemy라이브러리의 지원을 받기 때문인데요.

걱정하실 필요는 없는게, sqlalchemy라이브러리 내에 mysqlconnector가 있기 때문에 해당 connector를 사용해주기만 하면 됩니다.
상세 메서드는 공홈에서 참조하실 수 있습니다. 여기서는 적재가 목적이기 때문에 name, con외에 다른 파라미터는 사용하지 않았습니다.
pandas.DataFrame.to_sql — pandas 1.4.2 documentation
Specifying the datatype for columns. If a dictionary is used, the keys should be the column names and the values should be the SQLAlchemy types or strings for the sqlite3 legacy mode. If a scalar is provided, it will be applied to all columns.
pandas.pydata.org
샘플 데이터는 제 깃허브에서 가져왔습니다.(국내 코로나 확진자수 데이터입니다.)
data = pd.read_csv("https://raw.githubusercontent.com/ddongmiin/deepPythonAnalysis/master/interpretation/covid19_korea.csv"
, encoding= 'cp949')
# 혹시 모르니 영어로 컬럼명 변경
data.columns = ['tddate', 'confirmed_case_total', 'confirmed_case_korea', 'confirmed_case_overseas', 'dead']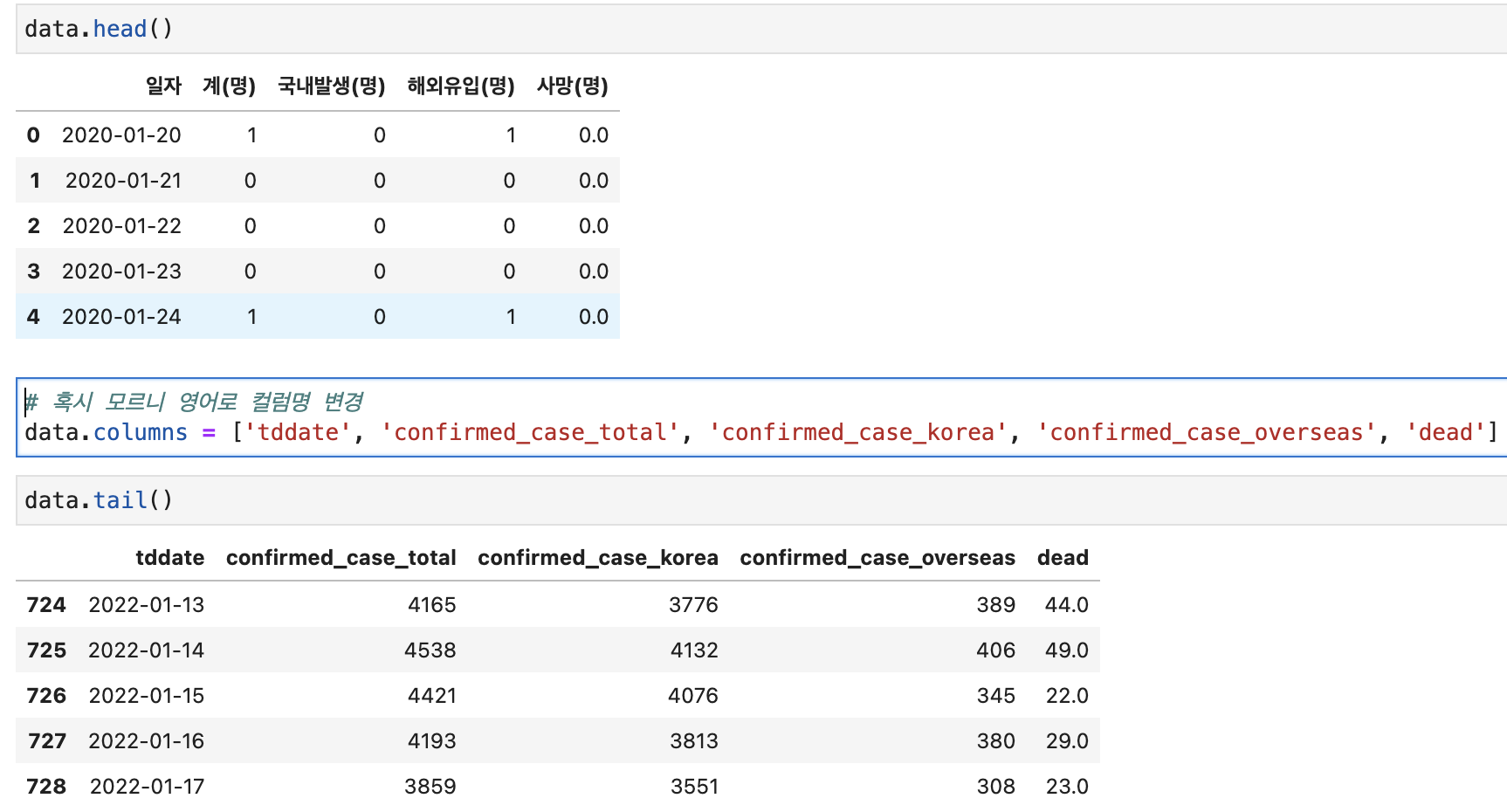
해당 데이터를 airflow_test_db에 적재해봅시다. index를 False로 설정하면 적재시 데이터프레임 내의 index번호를 drop합니다.
# to_sql
connection = sqlalchemy.create_engine(f"mysql+mysqlconnector://{user_name}:{pass_my}@{host_my}/{db_name}")
table_name = 'covid19_confiremed_case_cnt'
data.to_sql(name = table_name
,con = connection
,index = False)
Workbench내에서 SCHEMAS를 클릭하면 Tables 하위에 covid19_confirmed_case_cnt 테이블이 생성된것을 알 수 있습니다. 쿼리도 정상적으로 동작하네요. (쿼리는 작성후 번개 버튼을 클릭하거나 드래그 후 crtl(command)+enter를 입력하시면 됩니다.)
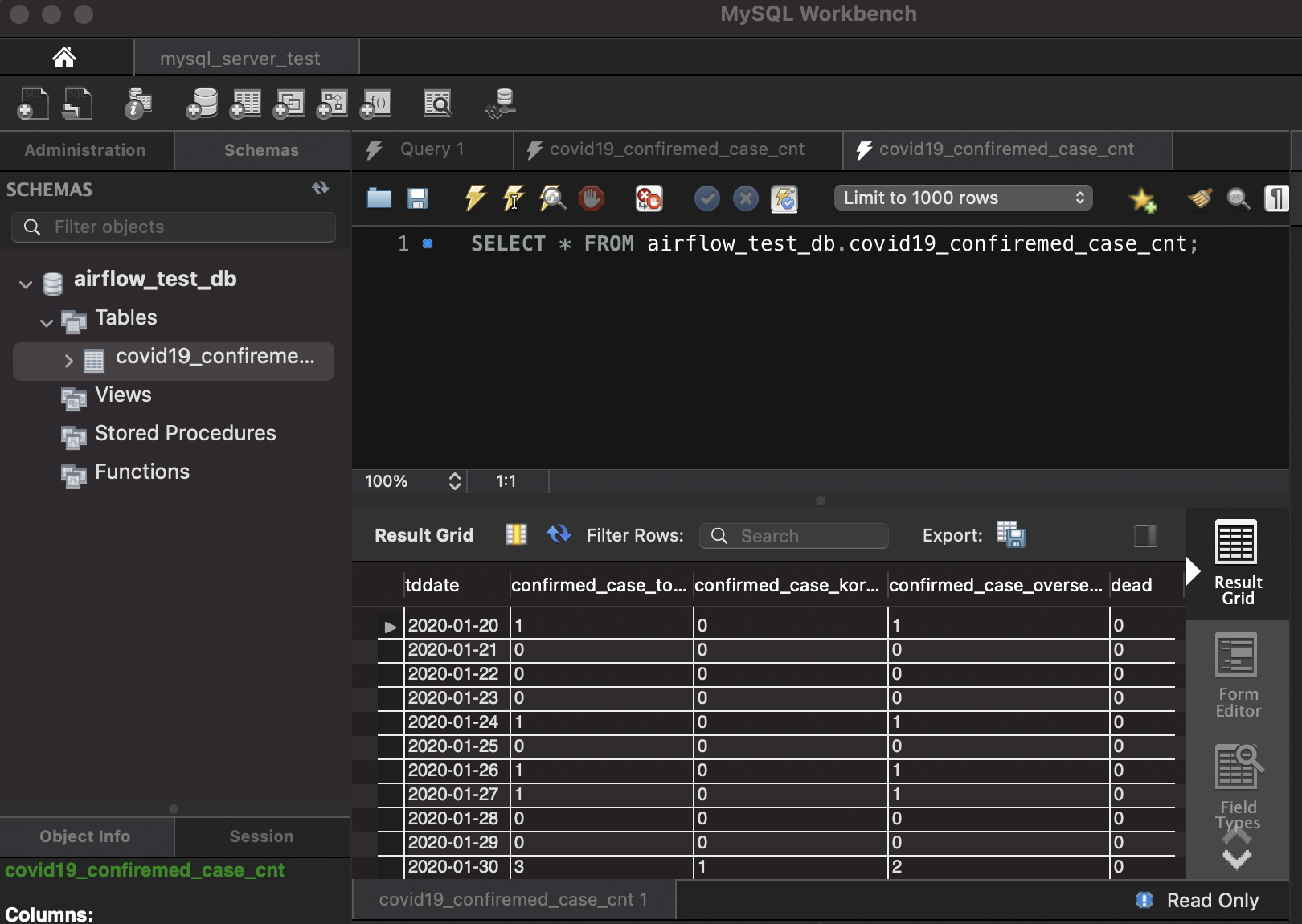
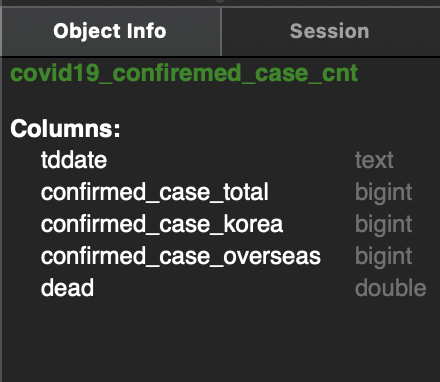
하단의 Object info를 살펴보면 아래와 같은 데이터가 들어온 것을 알 수 있습니다.
dtype파라미터를 이용하면 아래와 같이 dict형태로 타입을 지정할 수 있는데요. 아래와 설명과 같이 sqlalchemy내의 type들로 설정 가능한 것 같습니다. 모든 타입의 sql에서 지원하는지는 잘 모르겠네요. to_sql메서드를 지속적으로 사용하려면 sqlalchemy내에 어떤 타입을 지원하는지도 숙지하고 있어야 할 것 같네요.

dtype={'sample_col': sqlalchemy.types.JSON}https://docs.sqlalchemy.org/en/14/core/type_basics.html
Column and Data Types — SQLAlchemy 1.4 Documentation
Column and Data Types SQLAlchemy provides abstractions for most common database data types, and a mechanism for specifying your own custom data types. The methods and attributes of type objects are rarely used directly. Type objects are supplied to Table d
docs.sqlalchemy.org
이상입니다!
'딥상어동의 딥한 프로그래밍 > 엔지니어링' 카테고리의 다른 글
| Ganglia Web Interface 관련 링크 모음 (0) | 2022.07.29 |
|---|---|
| [Airflow] 데이터 적재 파이프라인 튜토리얼 - 서울시 지하철호선별 역별 승하차 인원 정보 적재하기 (2) | 2022.06.12 |
| [ubuntu]에서 jupyterlab background 서버 구축하기 (0) | 2022.05.24 |
| [Airflow] 리눅스 도커를 이용한 설치 삽질기 (1) | 2022.05.10 |
| [Airflow] 설치(pip install) 및 webserver 실행 (0) | 2022.05.08 |
제 블로그에 와주셔서 감사합니다! 다들 오늘 하루도 좋은 일 있으시길~~
포스팅이 좋았다면 "좋아요❤️" 또는 "구독👍🏻" 해주세요!
![[Airflow] 데이터 적재 파이프라인 튜토리얼 - 서울시 지하철호선별 역별 승하차 인원 정보 적재하기](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2F381v0%2FbtrEAzve8h2%2FAAAAAAAAAAAAAAAAAAAAADJFJmsLo8r8SDBY2XVI-lkaYr8T131NMVltGxBhorLF%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1764514799%26allow_ip%3D%26allow_referer%3D%26signature%3DmpVyLktYKZ3og6x9lj4q5S%252BHO8w%253D)
![[ubuntu]에서 jupyterlab background 서버 구축하기](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FLrYOy%2FbtrCYivrqfi%2FAAAAAAAAAAAAAAAAAAAAAKR0MdjjCm7vkcpbDbhm7FRnfEqzetm_YgULasksPVZW%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1764514799%26allow_ip%3D%26allow_referer%3D%26signature%3DLQIibO6U%252BRNk3djwAwHWkkHb58g%253D)
![[Airflow] 리눅스 도커를 이용한 설치 삽질기](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2Fq4j2e%2FbtrBtDiinDA%2FAAAAAAAAAAAAAAAAAAAAAPM8RACdTLdl8Fp7bvHsT9Dp32vmRWMDXarufG2HYe83%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1764514799%26allow_ip%3D%26allow_referer%3D%26signature%3DH365a0fN4VVqckjlwnlkzBTVoSg%253D)