![[Pandas] 퍼널차트 데이터프레임으로 표현해보기](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2Fd4bGge%2Fbtrb6T4hpKK%2FVE6Zk7JYw7HgAZL1PSwlr0%2Fimg.jpg)

0. 퍼널 차트
몇 명이나 깔때기를 통과할까?


좌측 퍼널 차트는 얼마나 많은 방문자를 구매자로 전환시킬 수 있을까?에 대한 고민을 담고 있습니다. 이처럼, 퍼널 차트는 "서비스의 목표"와 관련이 있습니다. 대표적인 예로 AARRR 모형(우측)이 있습니다.
1. Acquisition : 유저 유입
2. Activation : 첫 활동 (회원가입)
3. Retention : 재방문
4. Revenue : 서비스 구매
5. Referral: 주변인에게 추천
직관적으로, 퍼널 단계가 아래로 갈수록 (= 깔때기가 좁아질수록) 통과 난이도가 어려워진다는 것을 알 수 있습니다. 예를 들어, 현재 서비스의 목표가 "회원가입"이라고 가정합시다. 당연히 유입 유저수 != 회원가입 유저수일 텐데요. 이때, 회원가입까지 이루어지는 과정 중 어떤 단계에서 유저들이 이탈하는지 살펴보면 목표 달성(=회원가입)의 방해 요인을 확인할 수 있습니다.
결론적으로, 퍼널 차트를 그리는 이유는 서비스의 목표 달성을 방해하는 병목 현상을 발견하기 위해서라고 할 수 있습니다.
1. 작성 배경
하지만 저는 퍼널 차트를 설명하려고 이 글을 작성하지는 않았습니다.

어느날, Medium에서 우연찮게 funnel chart를 그리는 방법에 대해 보게 되었는데요. plotly에는 funnel이라는 함수가 따로 있어 funnel 차트를 굉장히 편하게 그릴 수 있게 되어 있더라고요!
https://plotly.com/python/funnel-charts/
그런데, 문서를 보다가 문득 이런 생각이 들었습니다.
담고 있는 정보량에 비해서 차지하는 면적이 너무 넓은 것 아닌가?


그래서, 다음 두 가지에 대해서 고민하고 글을 작성하게 되었습니다.
1. 퍼널 차트를 데이터 프레임으로 형태로 나타내면 어떨까?
2. 그렇게 하기 위해서는 데이터를 어떻게 집계해야 할까?
주의 ⚠️ ☠️ 본 문서는 다량의 노가다를 함유하고 있음
2. 퍼널 차트 -> 데이터 프레임(퍼널이 순서대로 진행되는 경우)
import pandas as pd
import numpy as np
from itertools import permutations
import copy필요한 라이브러리들을 임포트 해주고
2-1. 샘플 데이터 생성
def arrayToDf(phase_name: str, array, col_name: str) -> pd.DataFrame:
"""
array를 받아서 원하는 범주에 할당하여 데이터프레임을 생성합니다.
"""
dfFromArray = pd.DataFrame(data=array, index=[phase_name]*len(np_array), columns=[col_name]).reset_index()
dfFromArray.columns = ['category', col_name]
return dfFromArray
user_a = np.arange(100)
user_b = np.arange(70)
user_c = np.arange(50)
user_d = np.arange(30)
user_df = pd.DataFrame()
for np_array, category in zip([user_a, user_b, user_c, user_d], ['phase1', 'phase2', 'phase3', 'phase4']):
user_df = pd.concat([user_df, arrayToDf(category, np_array, 'userId')])
위와 같이 phase1 ~ phase4까지 4단계의 절차가 있는 서비스를 가정하고 userId를 생성했습니다.
2-2. 퍼널 데이터 프레임 생성
def make_funnel(df: pd.DataFrame, category: str, userid: str, phase_list: list) -> pd.DataFrame:
"""
퍼널 데이터 형식의 데이터프레임을 출력해줍니다.
-------------param--------------
df: 데이터프레임
category: 퍼널단계 컬럼명
userid : 유저아이디 컬럼명
phase_list: 퍼널 단계 리스트
"""
empty_list = []
intersectArray = np.array(df.loc[(df[category] == phase_list[0]), userid]) #array 초기화
initialCnt = len(intersectArray) #모수
phase_name = phase_list[0] #시작 퍼널
for phase in phase_list:
phaseArray = np.array(df.loc[(df[category] == phase), userid]) #단계별 유저수
intersectArray = np.intersect1d(intersectArray, phaseArray) #퍼널 통과 유저 array
intersectCnt = len(intersectArray) #퍼널 통과 유저수
phase_name = str(phase_list.index(phase) + 1) +'.' + phase #퍼널 단계 이름을 생성합니다.
empty_list.append(["->".join(phase_list), phase_name, intersectCnt, intersectCnt/initialCnt])
df = pd.DataFrame(data=empty_list, columns = ['퍼널이름', '퍼널단계', '유저수', '전환율'])
return df
본 함수는 다음과 같이 구성되어 있습니다.
1. 퍼널 최초 단계의 유저 리스트를 받는다.
2. 다음 단계의 유저 리스틀 받는다.
3. 일치하는 유저가 있는지 교집합을 확인한다. (= 퍼널 통과 유저)
4. 3번의 유저 리스트로 array를 다시 정의한다.
5. 퍼널 리스트 크기만큼 2~4 반복
여기서 잠깐❗️, 생각해보면 그냥 단계별로 유저수를 groupby 하면 될 텐데 왜 굳이?라는 생각이 들 수도 있습니다. 저도 비슷한 생각을 했고요. 다만, 퍼널의 의미상 "이전 단계를 통과했는지 체크"하는 부분이 연산에 포함되어야 하지 않나 싶어 위와 같이 함수를 구성했습니다.
testDf = make_funnel(user_df, 'category', 'userId', ['phase1', 'phase2', 'phase3', 'phase4'])
#한 번에 여러 스타일을 적용해야함.
testDf.style.format({'전환율':'{:,.1%}'.format})\ #%형태로 포메팅
.set_properties(**{'text-align': 'left'})\ #왼쪽 정렬
.bar(subset=['전환율'], width=100, align='left', vmin=0, vmax=1)\
.set_table_styles(
[{"selector": "", "props": [("border", "1px solid grey")]},
{"selector": "tbody td", "props": [("border", "1px solid grey")]},
{"selector": "th", "props": [("border", "1px solid grey")]}])

몇 가지, style 문법을 적용하면 위와 같이 퍼널 차트를 데이터 프레임 형태로 표현해볼 수 있습니다.
참고로, style 메서드를 사용하면 데이터프레임 객체 타입이 다음과 같이 바뀌게 됩니다.
pandas.io.formats.style.Styler
따라서, 이후 더 이상의 변환은 어려워지게 되는데요. 그렇기 때문에 style 메서드를 적용할 때는 한 번에 모든 메서드를 이어서 사용해야 합니다.
여기서 핵심이 되는 부분은
.bar(subset=['전환율'], width=100, align='left', vmin=0, vmax=1) 인데요. vmin과 vmax를 0~1로 설정해주면 바의 최소 최댓값이 0~1로 설정되어 위와 같이 100%=전체 면적 형태로 표현할 수 있게 됩니다.
3. 퍼널 차트 -> 데이터 프레임(퍼널이 순서대로 진행되지 않는 경우)
추가적으로, 건너뛰기나 다음에 하기와 같은 기능이 있어 모든 퍼널이 순서대로 진행되지 않는 경우에 대해서 생각해 봤습니다. 예를 들면, 2단계는 생략하고 1, 3, 4단계만 할 수 있거나 3단계는 생략하고 1, 2, 4단계만 진행할 수 있는 경우 등입니다.
우선, 전체 퍼널 리스트에서 가능한 모든 "서브 퍼널 리스트"들을 생성해야 합니다. 여기서 가장 중요한 것은 서브 퍼널 리스트의 원소들이 퍼널 단계 별로 정렬되어 있어야 한다([1, 3, 2] -> [1, 2, 3])는 것입니다. 퍼널 리스트의 인덱스를 이용하여 퍼널 단계를 호출하는 방식으로 함수를 구성해 봤습니다.
3-1. 단계별 퍼널 리스트 생성
def funnelNameList(cntPhase: int, check: list = []) -> list:
"""
퍼널 리스트를 인덱스 형식으로 구성합니다.
-------------param--------------
cntphase: 퍼널 구성 요소 수
check: 반드시 통과해야할 퍼널 단계를 리스트로 입력해줍니다.(0부터 시작)
"""
empty_list = []
array = [i for i in range(1, cntPhase)]
for i in range(1, len(array)+1):
empty_list.extend(permutations(array, i))
sorted_list = list(set(["".join(sorted([str(k) for k in element])) for element in empty_list]))
final_list = [[0] + [int(k) for k in list_a] for list_a in sorted_list if set(check).issubset([int(k) for k in list_a]) == True]
final_list.append([0]) #최초 단계 리스트
return final_list
본 함수는 다음과 같이 구성되어 있습니다.
기본적인 아이디어
퍼널의 최초 단계를 제외한, 나머지 단계들을 이용하여 순열 리스트를 만듭니다. 최초 단계를 제외한 이유는 나머지 단계들을 이용하여 만든 리스트의 제일 앞자리에 [0](=최초 단계)만 더해주면 되기 때문입니다.
작동 방식
1. Permutation 라이브러리를 이용하여 인덱스 개수 별로 리스트를 생성해줍니다.
2. index 리스트를 str 형태로 join 하여 붙여줍니다.
3. sorted와 set을 활용하여 "134" / "143" 다음과 같은 문자열들을 "134" 하나의 문자열로 만들어줍니다.
4. 다시, str을 int로 변환하여 인덱스 리스트를 만들어 줍니다. "134" -> [1, 3, 4]
5. 이때, 반드시 통과해야 할 퍼널 단계가 포함되어 있는지 체크해줍니다. set(check).issubset([])
예를 들어, 두 번째 퍼널 단계를 필수적으로 통과해야 하는 경우의 퍼널 리스트를 출력해보겠습니다.
funnelNameList(cntPhase = 4, check = [1]) #index는 0부터 시작
3-2. 기존 make_funnel 함수 수정
2-2에서 정의했던 함수를 수정할 필요가 생겼습니다. 왜냐하면, [0, 1]과 같이 퍼널 도달 지점이 명확하게 정의되지 않은 서브퍼널리스트가 생성되었기 때문입니다. 따라서, 이런 경우 두 번째 퍼널까지 도달 후 이탈 이런 식으로 정의를 해주어야 합니다.
def make_funnel2(df: pd.DataFrame, category: str, userid: str, subFunnel: list, allFunnel: list) -> pd.DataFrame:
"""
퍼널 데이터 형식의 데이터프레임을 출력해줍니다.
-------------param--------------
df: 데이터프레임
category: 범주형변수 컬럼명
userid : 유저아이디 컬럼명
subFunnel: 서브 퍼널
allFunnel : 전체 퍼널
"""
empty_list = []
Array = np.array(df.loc[(df[category] == subFunnel[0]), userid]) #array 초기화
initialCnt = len(Array) #모수
phase_name = subFunnel[0] #시작 퍼널
#서브퍼널리스트의 마지막 단계가 전체퍼널리스트의 마지막 단계와 일치하는 경우(=퍼널 도달 지점이 있는 경우)
if subFunnel[-1] == allFunnel[-1]:
for phase in subFunnel:
phaseArray = np.array(df.loc[(df[category] == phase), userid])
Array = np.intersect1d(Array, phaseArray) #퍼널 통과 유저 array
Cnt = len(Array)
phase_name = str(phase_list.index(phase) + 1) +'.' + phase
empty_list.append(["->".join(subFunnel), phase_name, Cnt, Cnt/initialCnt])
#서브퍼널리스트의 마지막 단계가 전체퍼널리스트의 마지막 단계와 일치하지 않는 경우(퍼널 도달 지점이 없는 경우) -> 이탈로 정의
else:
"""
만약, 서브퍼널리스트의 마지막 단계가 전체퍼널리스트의 마지막 단계와 일치 하지 않는 경우
이탈로 정의하고 이탈 유저를 정의하기 위해 전체퍼널리스트와 서브퍼널리스트의 차집합을 추가
"""
funnel = copy.deepcopy(subFunnel) #깊은 복사 _ 원본 서브퍼널리스트 보존
funnel.append(list(set(allFunnel) - set(subFunnel)))
for phase in funnel:
if phase != funnel[-1]:
phaseArray = np.array(df.loc[(df[category] == phase), userid])
phase_name = str(funnel.index(phase) + 1) +'.' + phase
Array = np.intersect1d(Array, phaseArray) #퍼널 통과 유저 array
Cnt = len(Array)
else:
"""
이탈인 경우 isin 메서드를 이용하여 서브퍼널리스트에 포함되지 않은 모든 단계의 유저들과 차집합 연산
"""
phaseArray = np.array(df.loc[(df[category].isin(phase)), userid])
phase_name = str(funnel.index(phase) + 1) +'.' + '이탈'
Array = np.setdiff1d(Array, phaseArray) #퍼널 미통과 유저 array
Cnt = len(Array)
empty_list.append(["->".join(subFunnel) + "->이탈", phase_name, Cnt, Cnt/initialCnt])
df = pd.DataFrame(data=empty_list, columns = ['퍼널이름', '퍼널단계', '유저수', '전환율'])
return df
본 함수는 다음과 같이 구성되어 있습니다.
서브퍼널리스트의 마지막 도달 지점이 전체퍼널리스트의 마지막 도달 지점과 일치 하는 경우
2-2와 동일한 방식으로 연산 수행
서브퍼널리스트의 마지막 도달 지점이 전체퍼널리스트의 마지막 도달 지점과 일치하지 않는 경우
1. 서브퍼널리스트에 대해서는 2-2와 동일한 방식으로 연산 수행
2. 이후 차집합(전체퍼널리스트 - 서브퍼널리스트)의 유저들과 차집합 연산 수행 -> 이탈 유저로 정의
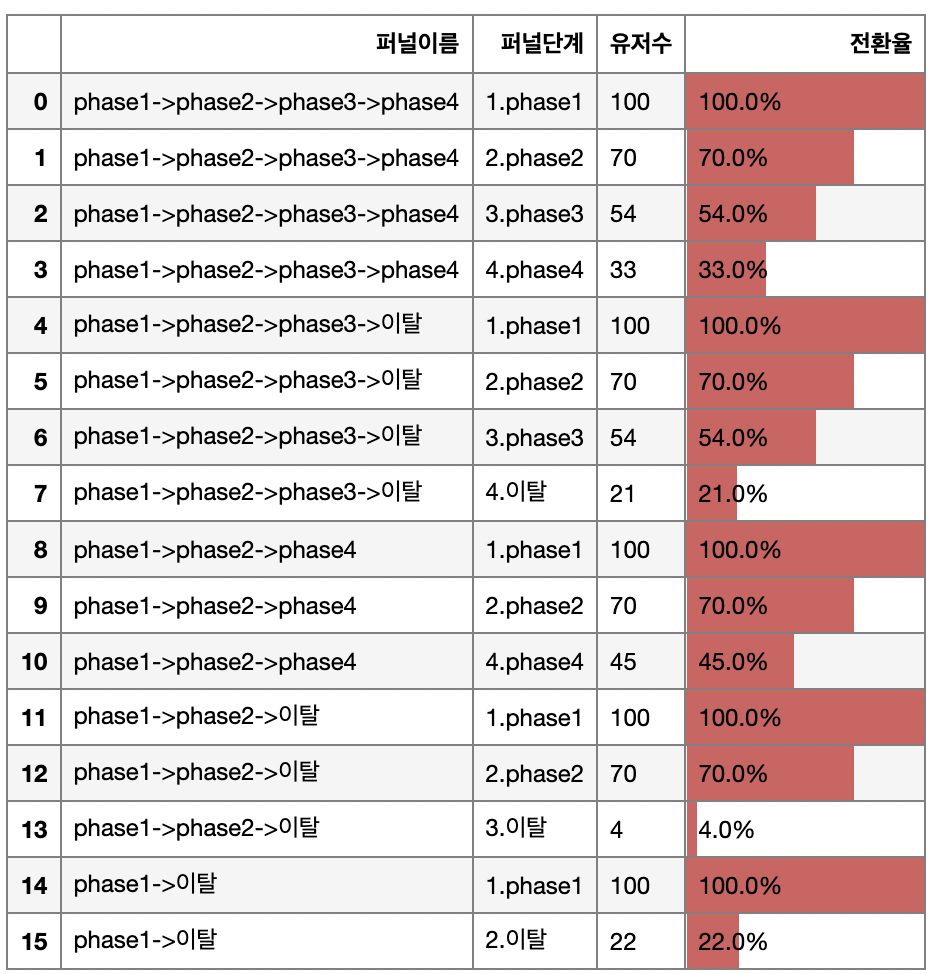
예를 들어, 퍼널 단계가 총 4단계이고 두 번째 퍼널이 통과가 필수인 경우의 데이터 프레임을 출력해 보겠습니다.
user_a = np.arange(100)
user_b = np.random.choice(range(10, 90), size=70, replace=False)
user_c = np.random.choice(range(10, 90), size=60, replace=False)
user_d = np.random.choice(range(10, 90), size=50, replace=False)
user_df = pd.DataFrame()
for np_array, category in zip([user_a, user_b, user_c, user_d], ['phase1', 'phase2', 'phase3', 'phase4']):
user_df = pd.concat([user_df, arrayToDf(category, np_array, 'userId')])
phase_list = ['phase1', 'phase2', 'phase3', 'phase4']
testDF2 = pd.DataFrame()
#두번째 퍼널 단계 통과가 필수인 경우
for funnel in funnelNameList(cntPhase = 4, check = [1]):
df = make_funnel2(user_df, 'category', 'userId', [phase_list[i] for i in funnel], phase_list)
testDF2 = pd.concat([testDF2, df])
#퍼널이름 및 단계별로 정렬
testDF2['idx1'] = testDF2['퍼널이름'].str.split('->').map(lambda x: len(x))
testDF2 = testDF2.sort_values(by=['idx1', '퍼널이름', '퍼널단계'], ascending=[False, True, True]).iloc[:, [0, 1, 2, 3]]
testDF2.reset_index(drop=True).style.format({'전환율':'{:,.1%}'.format})\
.set_properties(**{'text-align': 'left'})\
.bar(subset=['전환율'], width=100, align='left', vmin=0, vmax=1)\
.set_table_styles(
[{"selector": "", "props": [("border", "1px solid grey")]},
{"selector": "tbody td", "props": [("border", "1px solid grey")]},
{"selector": "th", "props": [("border", "1px solid grey")]}])
4. 결론
지금까지 퍼널 차트를 데이터프레임 형태로 표현해봤습니다.
퍼널 차트를 데이터프레임으로 표현했을 때, 전달하는 정보량 대비 사용되는 면적이 줄어드는가?
면적은 확실히 줄어드는 것으로 보입니다. 하지만, 전체 퍼널 구성을 표현하기 위해 "퍼널 이름" 항목을 추가해야 한다는 측면에서 시각적으로는 만족스럽지 못한 것 같습니다. 또한, 전환율을 표기하는 방식에 있어서도 엑셀에서 2차 작업을 해야 할 것 같다는 생각이 드네요.
퍼널 차트를 데이터프레임으로 표현하기 위해서는 어떻게 집계해야 하는가?
이전 단계의 userid와 현재 단계의 userid 간의 포함 관계를 비교해야 합니다. 포함 관계는 경우에 따라 차집합이 될 수도 있고 교집합이 될 수도 있습니다.
지금까지 개인적인 호기심에 몇 가지 코드를 작성해봤습니다. 읽어주신 분들 감사드립니다. 🙇🏻♂️
혹시 더 좋은 의견이나, 잘못된 부분이 있다면 편하게 댓글 부탁드리겠습니다!
Reference
https://stackoverflow.com/questions/64812819/pandas-dataframe-style-lost-table-border
pandas DataFrame style lost table border
I'm following instructions at https://pandas.pydata.org/pandas-docs/stable/user_guide/style.html to set up style for my data frame to become html. It worked well, except that the table's border of ...
stackoverflow.com
https://pandas.pydata.org/docs/reference/style.html
Style — pandas 2.2.2 documentation
Style Styler objects are returned by pandas.DataFrame.style. Styler constructor Styler(data[, precision, table_styles, ...]) Helps style a DataFrame or Series according to the data with HTML and CSS. Styler.from_custom_template(searchpath[, ...]) Facto
pandas.pydata.org
'딥상어동의 딥한 데이터 처리 > 시각화' 카테고리의 다른 글
| [Pandas] 데이터프레임도 이미지로 저장할 수 있다구? (1) | 2022.10.02 |
|---|---|
| [Boxplot] 박스플롯 이용시 주의사항 (2) | 2021.12.19 |
| Seaborn | countplot(기본 파라미터, x축 정렬하기, x축 라벨 회전) (0) | 2021.03.07 |
| [Matplotlib] 모두를 위한 Python시각화 - (1)Matplotlib.artist (2) | 2021.01.03 |
| 아카이브 페이지 (2) | 2021.01.01 |
제 블로그에 와주셔서 감사합니다! 다들 오늘 하루도 좋은 일 있으시길~~
포스팅이 좋았다면 "좋아요❤️" 또는 "구독👍🏻" 해주세요!
![[Pandas] 데이터프레임도 이미지로 저장할 수 있다구?](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FIeyHv%2FbtrNyEChk5v%2F7SXQ7hGKKOWXkpmQoa1NXk%2Fimg.png)
![[Boxplot] 박스플롯 이용시 주의사항](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FehG3yj%2FbtrohUbtCFz%2Fcs7FexdtRhZ5gKexdHeMJ0%2Fimg.png)

![[Matplotlib] 모두를 위한 Python시각화 - (1)Matplotlib.artist](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FbDijGG%2FbtqSjAWql3h%2FQR7afoVsqMdWl5CdsM62eK%2Fimg.png)