![[Pyspark] from pyspark.sql import * VS from pyspark.sql.functions import *](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2Fbu0YXE%2FbtryE2ZuPLs%2FAAAAAAAAAAAAAAAAAAAAABvkIvNkB56cWpKlDRlvVkuXoWvbuSXOUPAWcROIvLUl%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1764514799%26allow_ip%3D%26allow_referer%3D%26signature%3DEn75hEE88BfrUIFT26bWW2gq8nQ%253D)

오늘은 pyspark.sql 내 메서드들에 대해 알아보려 한다.
0. import pyspark.sql
https://spark.apache.org/docs/2.4.0/api/python/pyspark.sql.html#module-pyspark.sql.functions
pyspark.sql module — PySpark 2.4.0 documentation
Parameters: path – string, or list of strings, for input path(s), or RDD of Strings storing CSV rows. schema – an optional pyspark.sql.types.StructType for the input schema or a DDL-formatted string (For example col0 INT, col1 DOUBLE). sep – sets a s
spark.apache.org
우선, 공홈에 들어가보자.

pyspark.sql내에 어떤 함수들이 있는지 나와있다. 우선, 첫 번째로 가장 눈에 띄는 함수는 SparkSession이다.
SparkSession
The entry point to programming Spark with the Dataset and DataFrame API. (공홈참조)
SparkSession을 생성해야 Spark내에 있는 Dataset과 DataFrame API를 사용할 수 있다. 특히, SparkSession 아래에는 createDataFrame라는 함수가 있는데 spark DataFrame을 생성할 때 사용하는 함수이다.
#공홈참조
spark = SparkSession.builder \
... .master("local") \
... .appName("Word Count") \
... .config("spark.some.config.option", "some-value") \
... .getOrCreate()
데이터 브릭스를 이용하면 아래와 같이 spark라는 변수 아래에 SparkSession이 기본적으로 생성되어 있다.

1. import pyspark.sql.functions
다음으로, pyspark.sql.functions이다. pyspark.sql.functions에는 RDD DataFrame에 사용할 수 있는 다양한 함수들이 있다. 사실, hive sql내에 있는 함수들과 거의 유사하다.
#공홈예제
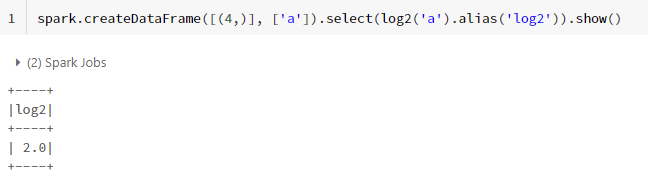
spark.createDataFrame([(4,)], ['a']).select(log2('a').alias('log2')).show()예를들어, 위와 같이 RDD DataFrame에 log2 function을 실행하면 아래와 같은 결과가 나온다.
2. from pyspark.sql.functions import *을 하지 않으면?

위와 같이 function내에 있는 함수가 정의되지 않았다는 오류가 발생한다.
'딥상어동의 딥한 프로그래밍 > Spark' 카테고리의 다른 글
| [PySpark] 자료 구조와 연산 원리 - 스파크 누구냐 넌? (4) | 2022.06.28 |
|---|---|
| [mllib] Pyspark Kmeans 알고리즘 사용법 (0) | 2022.04.08 |
| [PySpark] Python 내장 함수 사용시 발생하는 오류 (0) | 2021.07.21 |
| 스파크의 실행 계획 (0) | 2021.04.21 |
| [scalaSpark] pivot과 unpivot (0) | 2021.02.06 |
제 블로그에 와주셔서 감사합니다! 다들 오늘 하루도 좋은 일 있으시길~~
포스팅이 좋았다면 "좋아요❤️" 또는 "구독👍🏻" 해주세요!
![[PySpark] 자료 구조와 연산 원리 - 스파크 누구냐 넌?](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FbjIGfE%2FbtrFIc7jjiO%2FAAAAAAAAAAAAAAAAAAAAAIagp2fTjzoLrJROmLcffcZb7h3bmI1UeHFNC5kEwgpQ%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1764514799%26allow_ip%3D%26allow_referer%3D%26signature%3DeNCzMIJi6AD0qWoGQqPca5jcbFQ%253D)
![[mllib] Pyspark Kmeans 알고리즘 사용법](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FtzEI7%2FbtryEyqO1h2%2FAAAAAAAAAAAAAAAAAAAAADYI0zs0_jH3hR8Xb6OShwWJawf6BBVkTRGNPBTUTpcC%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1764514799%26allow_ip%3D%26allow_referer%3D%26signature%3D7nCqvGoulfWFC3ty14ikvz3L5AY%253D)
