![[PySpark] 자료 구조와 연산 원리 - 스파크 누구냐 넌?](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FbjIGfE%2FbtrFIc7jjiO%2FGC0CEDGCAuxW1gqbthEKrk%2Fimg.png)


핵심내용
스파크의 고유한 자료 구조와 연산 특징에 대해서 다루어보고자 합니다. ※스파크 설치 방법에 대해서는 다루지 않습니다.
대신 간단한 데이터브릭스 샘플 코드를 포함합니다.
본 글에서 다루는 내용
1. 데이터브릭스 커뮤니티에디션 이용 방법
2. Map reduce vs Spark
3. Driver와 Executor
4. RDD
5. Transformation
6. DataFrame
데이터브릭스 커뮤니티에디션
1. Try Databricks에 접속한다.
https://databricks.com/try-databricks
Try Databricks - Unified Data Analytics Platform for Data Engineering
Discover why businesses are turning to Databricks to accelerate innovation. Try Databricks’ Full Platform Trial free for 14 days!
databricks.com
2. 기본적인 인적사항들을 입력해준다.
3. Get started with Comminuity Edition을 클릭한다.
※참고로, 2주 Free trial을 이용해도 인프라 환경에 대한 비용은 지불하셔야 됩니다. 그리고, 그것은 꽤 놀라게 하는 당신을 할 수도 있다.
최근 들어, 생성과정 UI가 달라져 달라진 부분만 캡쳐하였습니다. 이외 클러스터 생성 방법 및 노트북 이용 방법은 아래 블로그 내용을 참고 부탁드립니다.
http://i5on9i.blogspot.com/2021/03/databricks-apache-spark.html
[컴] Databricks 이용해서 apache spark 사용해보기
데이터브릭 / 아파치 스파크 테스트 / 스파크클라우드 / 간단히 테스트/ 사용해보기 / spark helloworld Databricks 이용해서 spark 사용해보기 overview 대략적인 순서는 아래와 같다. Try Databricks ...
i5on9i.blogspot.com
스파크란? VS Map Reduce
자동차로 비유하자면, 일종의 성능 좋은 엔진이라고 할 수 있습니다. 그리고, 사용자들은 Python/Scala/R/Java/SQL같은 프로그램을 이용해서 이 자동차를 운전합니다.
왜 사용할까? 여러가지 이유가 있겠지만, 보통 가장 강조하는 측면은 속도입니다. 2014년 글입니다. 동일한 데이터를 hadoop에 비해 무려 x3배 빨리! 10개나 적은 머신수로 처리했다고 나오네요.
Apache Spark Officially Sets a New Record in Large-Scale Sorting
Learn how by using Spark on 206 EC2 machines, Databricks sorted 100 TB of data on disk in 23 minutes and won the Daytona GraySort contest.
databricks.com
그럼 스파크 이전에는 아무것도 없었는가? 아닙니다. Map Reduce라는 분이 계셨습니다.
(reduce의 결과가...?)

대용량의 데이터를 블락으로 나누어 처리하는 시스템인데요. 군생활로 비유해보자면 아래와 같습니다. 일반 병사의 군생활은 크게 4가지 단계(이병, 일병, 상병, 병장) 로 나눌 수 있습니다(Split). 그리고, Split된 조각들 안에서 일어나는 각각의 활동을 횟수와 매칭할 수 있습니다(mapping). 다음으로, 비슷한 일들끼리 묶어줍니다(shuffling). 그리고, 하나로 합쳐줍니다(Reducing). 이렇게 불침번 N회, 훈련 M회, 행군P회를 하게되면 최종적으로는 전역?을 하게 되는거죠.
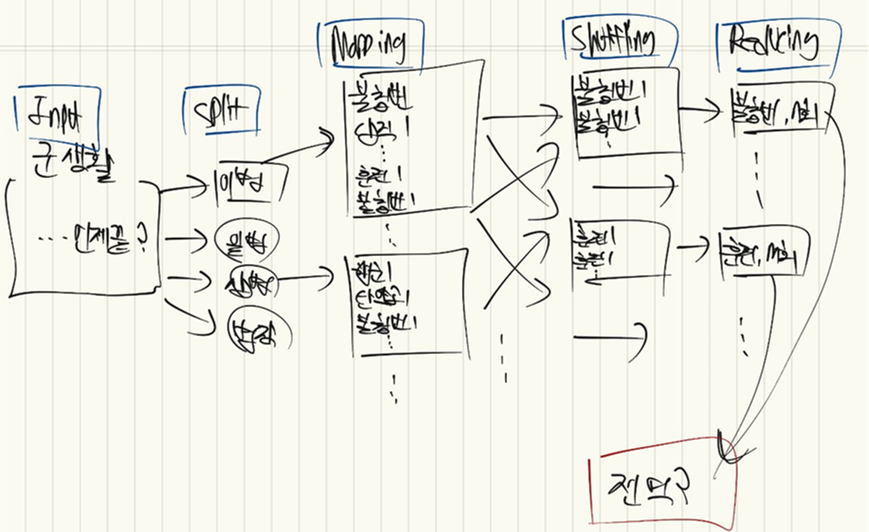
이와 같은 Map Reduce 시스템을 개선시킨 것이 spark입니다. 어떤 부분을 개선 시켰을까요? Map Reduce의 경우 각 단계(map, shuffling, reducing)마다 데이터를 HDFS(Hadoop file system)에 저장해야 합니다. 반면, 스파크의 경우....
In-memory Processing
데이터를 memory위에 올려두고 작업하게 됩니다. 이걸, in-memory processing이라고 하는데요. quora에 굉장히 좋은 비유가 있어서 첨부합니다.
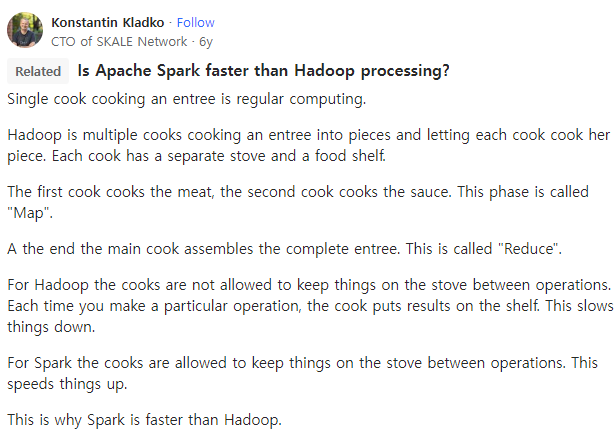
병렬처리를 일종의 요리과정에 비유한다면, spark의 경우 요리 재료가 stove에 계속 있는 상황이라 별도로 재료를 stove에 넣는 과정없이 계속해서 요리를 할 수 있다. 반면, hadoop의 경우 요리할때마다 재료를 넣어줘야 한다!
왜 stove에 요리가 계속 있는지는 논리적으로 이해되지 않지만, 어쨌든 계속해서 재료를 넣어주는 것보다는 stove안에 있는 재료들을 계속해서 재활용할 수 있다면 훨씬 효율적이겠죠?
Driver와 Executor
스파크에는 두 가지 연산 프로세서가 있습니다. 하나는 Driver고 다른 하나는 Executor인데요. Driver를 꿀벌(Executor, worker node)들에게 일감을 나눠주는 여왕벌이라고 생각할 수 있습니다.
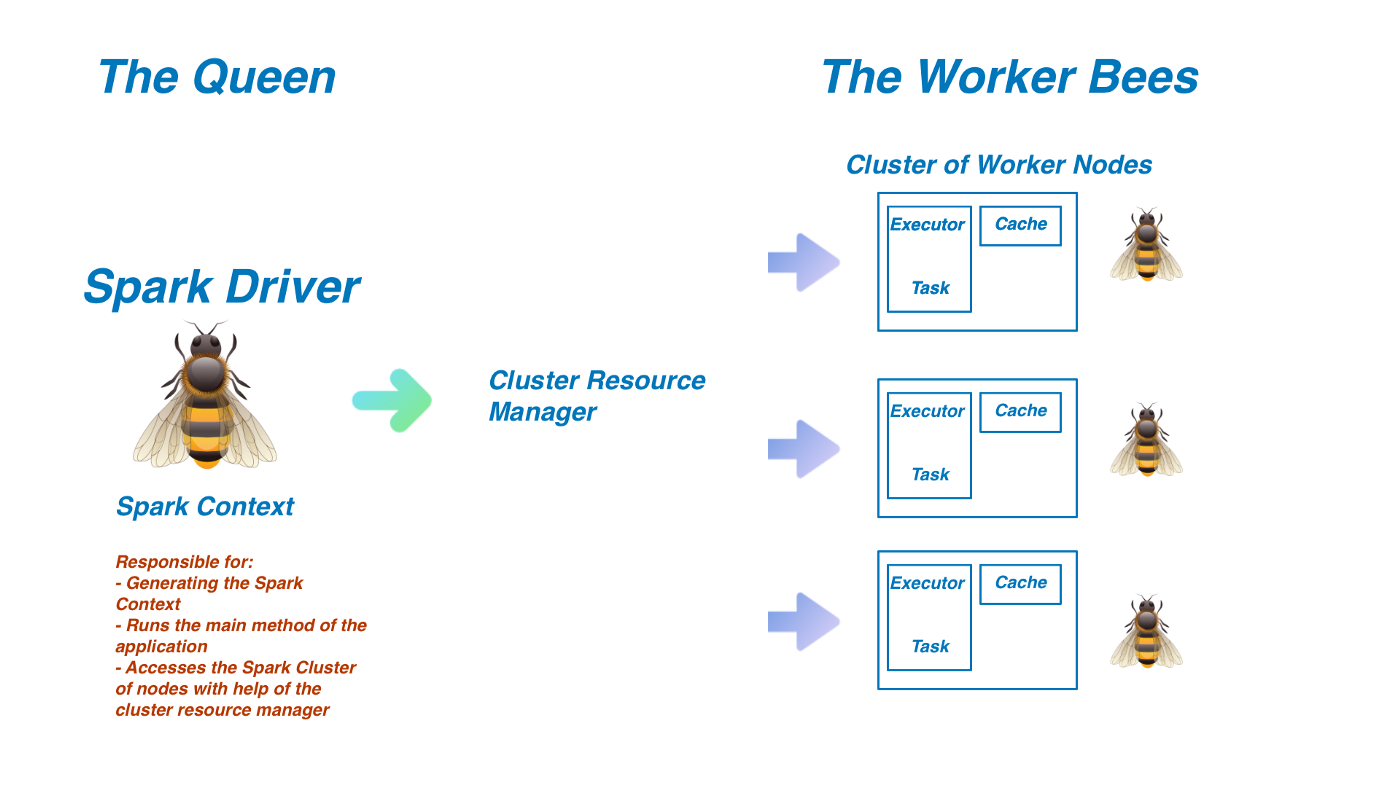
sparkContext란?
spark context는 driver 프로세서의 일종으로 sparkContext를 통해 RDD를 생성할 수 있습니다.
from pyspark import SparkContext, SparkConf
conf = SparkConf().setAppName(appName).setMaster(master)
sc = SparkContext(conf=conf)
데이터브릭스와 같은 제품 내에는 sc라는 변수로 sparkContext가 자동으로 생성되어 있습니다.

그리고 sparkContext(=sc)라는 driver processor를 이용해서 아래와 같이 3개의 파티션으로 나뉘어진 rdd를 생성할 수 있습니다.
rdd_sample_list = [i for i in range(10)]
rdd1 = sc.parallelize(rdd_sample_list, 3)
rdd1.getNumPartitions()
그리고, 파티셔닝 숫자를 조절할 수도 있습니다.
# 다시 파티셔닝을 할 수도 있음
rdd1.repartition(7).getNumPartitions()
sparkSession이란?
sparkContext의 업그레이드 버젼으로 생각하시면 될 것 같습니다. sparkSession을 이용하면 rdd외에도 DataFrame, DataSet을 생성할 수 있습니다. spark 2.0이상 버젼에서는 거의 대부분의 작업을 spark session으로 진행한다고 생각하셔도 될 것 같습니다.
마찬가지로 원래는 아래와 같이 SparkSession을 생성해야 하지만,
spark = (SparkSession
.builder
.appName("Python Spark SQL basic example")
.config("spark.some.config.option", "some-value")
.getOrCreate())
데이터 브릭스 내에는 아래와 같이 SparkSession이 미리 생성되어 있습니다.

그리고, SparkSession을 이용해 아래와 같이 spark DataFrame을 생성할 수 있습니다.
data = [('치킨', '너무비싸'), ('피자', '도너무비싸')]
columns = ['food', 'price']
df = spark.createDataFrame(data=data, schema = columns)

Executor - 그럼나는?
지금까지 얘기한, sparkContext와 sparkSession은 driver processor입니다. 여기까지만 얘기하면 Executor가 섭섭해할 것 같습니다만.. 어쨌든, Executor는 Driver processor의 명령을 실행하는 일꾼으로 볼 수 있습니다.

Driver Processor는 executor에게 구체적인 명령어를 지시합니다(Rdd를 만들어라, DataFrame을 만들어라 등등). 그리고, 그 일을 할 때 executor가 몇명이나 필요할지도 결정하죠. 예를 들어, 물 한잔 뜨는데 executor가 세명이나 있을 필요는 없습니다. 한 명이면 족하죠. 그리고, executor는 그 일을 충실히 수행하고 Driver한테 다시 보고합니다.
RDD
지금까지, Driver Processor를 이용해서 각각 RDD와 DataFrame API를 이용할 수 있다는 말씀을 드렸는데요. 모든 자료구조의 근간이 되는 RDD의 특징에 대해 간단히 다루고 넘어가겠습니다.
한번 RDD는 영원한 RDD다!
RDD가 가진 특성을 언급할 때, 가장 자주 나오는 것이 immutable함입니다. 변하지 않는 다는 뜻인데요. Pandas의 경우 기존 데이터 프레임을 이용하여 새로운 데이터 프레임을 만들 때마다 copy를 해주어야 합니다. 반면, 하나의 RDD를 원 상태로 보존하면서 계속해서 새로운 RDD를 계속해서 만들 수 있습니다. 왜냐하면, RDD가 immutable하기 때문입니다. 한번 생성한 RDD는 변하지 않습니다.
rdd_sample_list = [i for i in range(10)]
rdd1 = sc.parallelize(rdd_sample_list, 3)
rdd2 = rdd1.map(lambda x: x*x)
print(rdd1.collect())
print(rdd2.collect())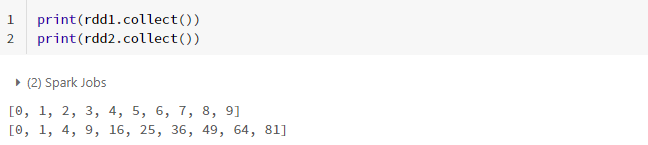
위와 같이 rdd1을 이용해서 rdd2를 만들었다 해도 rdd1에는 아무런 일도 일어나지 않습니다. 심지어, copy를 하지 않았는데도 말이죠.
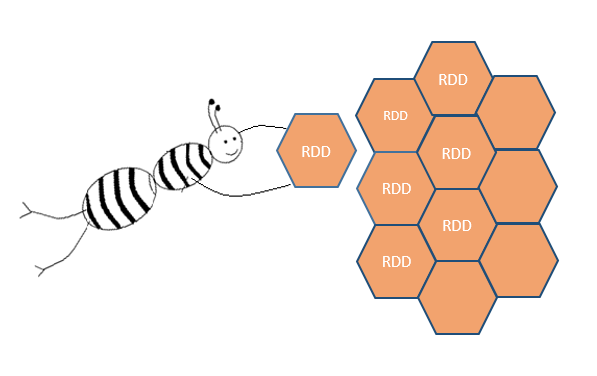
in-memory에 그저 또 하나의 rdd가 얹어질 뿐입니다.
에러에 관대한 RDD feat. fault-tolerance

RDD는 에러에 관대합니다. 이것을 fault-tolerance라고 하는데요. 그렇다면, 관대하다는 것은 무엇이고 왜 관대한 것인지 한번 따져보겠습니다. 우선, 무엇을 보고 관대하다고 할까요? 아까 말씀드렸듯이, driver processor는 여러명의 executor들에게 일을 시킬 수 있습니다. 예를 들어, 만약 어떤 executor가 일을 하다가 뻗어버렸다고 합시다. 그러면, 다른 executor에게 다시 그 일을 시켜버리면 그만입니다. 이를, fault-tolerance라고 하고 cluster manager라는 친구가 작업 과정을 지켜보다가 error를 발견하면 귀신 같이 다른 executor에게 다시 작업을 부여합니다.
그렇다면, 왜 fault-tolerance 해야할까요? 왜냐하면, RDD가 immutable하기 때문입니다. 여기서 immutable하다는 것은 Driver의 실행계획을 의미합니다. RDD는 Driver의 실행계획을 온전하게 구현해야 합니다. 그래야, immutable할 수 있죠. 그리고, 그렇게 하기 위해 error가 발생하는 경우 다른 node에게 다시 작업을 시켜 어떻게든 작업을 완수합니다.
Transformation
Transformation은 "스파크의 연산자"라고 생각할 수 있습니다. 그리고 Transformation은 이론적으로는 무한히 중첩시킬 수 있습니다.
Lazy Execution(지연 연산)과 Action
아래 그림과 같이 Driver는 executor들한테 시킬 일을 무한하게 쌓아둘 수 있습니다. 그리고, 이렇게 Driver가 작업 사항을 생각만 하고 있을 때는 아무리 작업 사항이 많더라도 executor들은 꼼짝도 안하고 기다리고 있습니다.
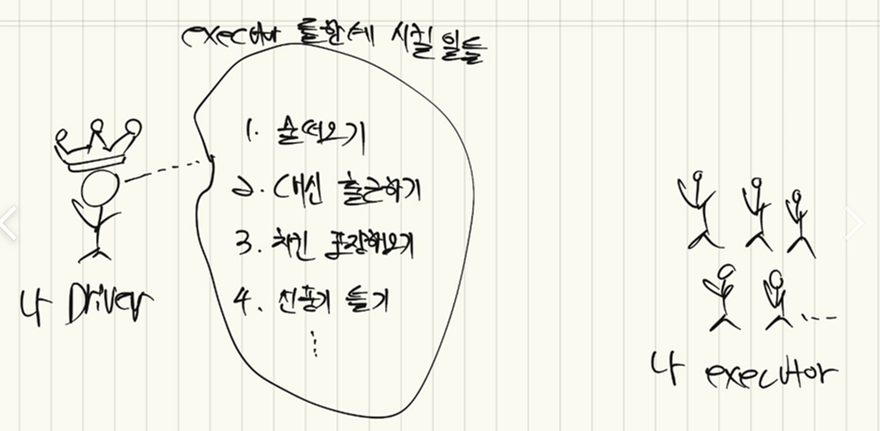
Driver가 executor들을 찾아야 그제서야 일을 시작하죠.

이를 지연 연산(lazy execution)이라고 합니다. Action을 하기 전에는 연산할 내용들을 아무리 많이 중첩해봐야 아무 일도 일어나지 않습니다.
# RDD 생성
flatmap_sample = sc.parallelize([2, 3])
# Transformation
flatmap_sample_v1 = flatmap_sample.flatMap(lambda x: range(1, x))
# action!
flatmap_sample_v1.collect()
위와 같이 transformation과 action의 단계는 명확히 구분됩니다. type을 찍어보면 좀 더 명확히 이해할 수 있는데요.
print("flatmap_sample", type(flatmap_sample))
print("flatmap_sample_v1", type(flatmap_sample_v1))
print("flatmap_sample_v1.collect()", type(flatmap_sample_v1.collect()))
flatmap_sample_v1까지는 RDD이고 여기에 collect()라는 action을 가했을 때 비로소 list라는 결과를 출력한 것을 알 수 있습니다. 참고로, PipelineRDD는 RDD의 일종으로 flatmap함수 연산이 더해진 RDD라고 생각하면 될 것 같습니다. 그러니까, 얘는 faltmap 함수를 실행해서 RDD를 만들거야 라는 일종의 마크 표시를 해두는거죠.
Narrow Transformation과 Wide Transformation
예를 들어, 말년 병장이 일병 이상 집합을 걸었다고 가정합시다.

이런 경우 input partition과 output partition의 관계는 1:1이라고 할 수 있고, 이를 narrow transformation이라고 합니다. 대표적인 연산으로 filter()가 있죠. 이런 경우 본인이 속한 partition만 살펴봐도 되기 때문에shuffle할 필요가 없습니다.
반면, 계급별로 병사 수가 몇명인지 숫자를 카운트 하는 경우
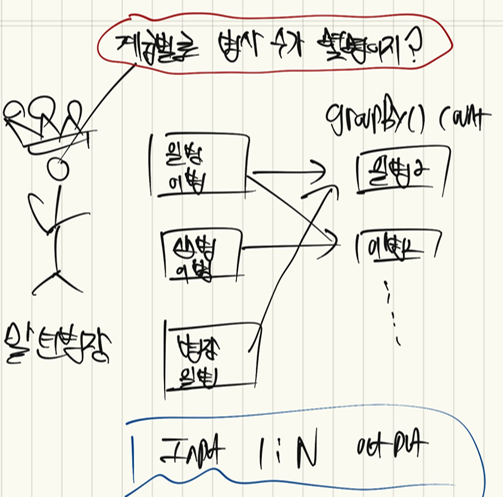
input partition과 output partition의 관계는 1:N이 됩니다. 그리고, 이를 wide transformation이라고 합니다. 대표적인 연산으로는 groupBy가 있습니다. 왜냐하면, 특정 그룹의 인자가 여러 partition에 퍼져 있기 때문입니다. 위 이미지에서도 일병과 이병은 각기 다른 파티션에 분할되어 있습니다. 그리고, 이와 같은 관계는 필연적으로 연산과정에 있어 shuffle을 수반합니다.
그래서, narrow transformation보다는 wide transformation에 더 많은 연산 비용을 소모할 수 밖에 없습니다. 이처럼 narrow와 wide의 차이는 input partitino에 대응하는 output partition의 수와 그에 따른 shuffle유무라고 할 수 있습니다.
DataFrame
이러한 RDD의 특성을 상속하여 고수준 API로 발전시킨 것이 DataFrame입니다.
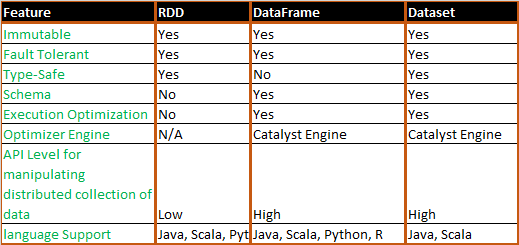
RDD의 주요한 특징을 모두 상속받으면서 여기에 Schema, Optimization과 관련된 기능이 추가된 것이 DataFrame이라고 할 수 있습니다.
타이타닉 데이터 셋을 불러와 Spark DataFrame으로 만들어보겠습니다.
import pandas as pd
titanic_pandas = pd.read_csv("https://raw.githubusercontent.com/datasciencedojo/datasets/master/titanic.csv")
pandas DataFrame을 spark.createDataFrame에 파라미터로 넣어주면 되는데요. (아까 말씀드렸듯이 spark는 sparkSession의 약자이고, sparkSession은 Driver processor입니다.)
# 판다스를 스파크로 변환
titanic_spark = spark.createDataFrame(titanic_pandas)
그리고, spark DataFrame은 View로도 만들 수 있는데요. View를 이용하면 SQL 문법을 적용하여 바로 결과를 확인할 수 있습니다.
titanic_spark.createOrReplaceTempView("titanic_qr")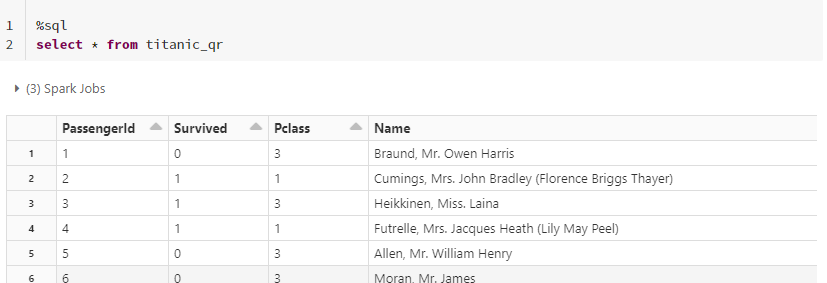
앞서 말씀드렸듯이, 스파크는 엔진의 일종이고 그 엔진은 다양한 언어들로 작동시킬 수 있습니다.
한번, spark SQL와 spark DataFrame의 실행계획을 비교해보겠습니다.
survival_rate_sql = spark.sql(f"""
select Pclass, avg(Survived) avg_survived
from titanic_qr
group by Pclass
""")
survival_rate_dataframe = titanic_spark.groupBy("Pclass").avg("Survived")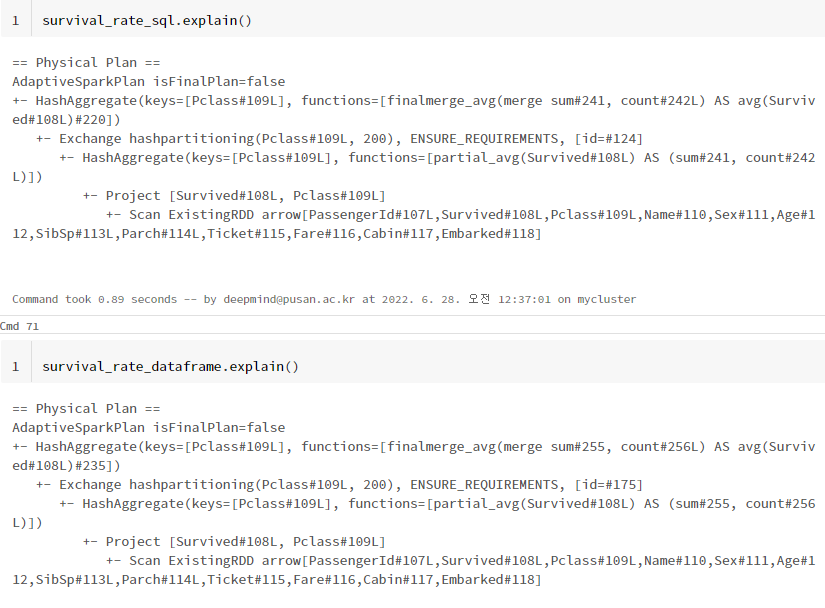
(실행 계획은 아래에서 위로 읽습니다.)
Spark DataFrame과 Spark SQL모두 동일한 실행 계획을 보여주고 있네요. 그렇기 때문에 DataFrame과 SQL문법 중 편한 것을 사용해도 무방합니다. 다만, DataFrame 문법을 이용했을 때 좀 더 코드가 짧은 것을 알 수 있습니다. 반대로, SQL을 사용할 줄 아는 사람에게는 SQL이 좀 더 가독성 있을 것 같습니다.
이외에도 아래와 같이 SQL에서 hint를 통해 partition 개수를 조정할 수도 있습니다.
%sql
select /*+ REPARTITION(16) */
Pclass, avg(Survived) avg_survived
from titanic_qr
group by Pclass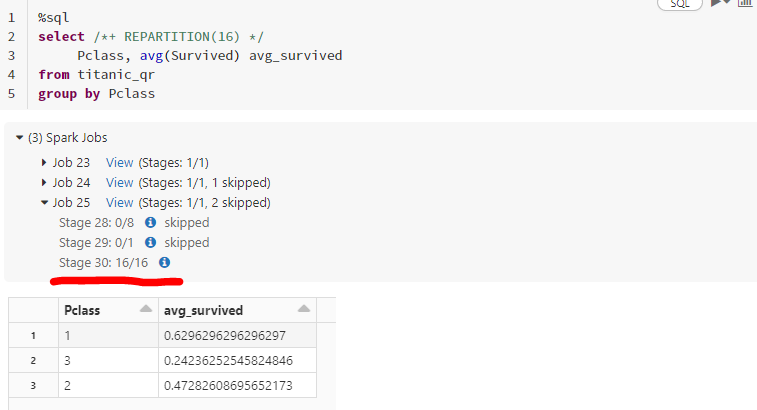
다만, partiton을 많이 나눈다고 무조건 좋은 것은 아닙니다. 앞서 말씀 드린 것처럼, 물 한잔을 16명이 떠올 필요는 없죠. 16명한테 작업을 나누느라 더 많은 시간이 걸릴 수도 있습니다.
지금까지, 스파크 자료 구조 특징과 연산 방식에 대해서 다뤄봤습니다. 읽어주셔서 감사합니다!
Ref.
https://towardsdatascience.com/spark-jargon-for-babies-and-python-programmers-5ccba2c60f68
Spark Fundamentals for Python Programmers
Everything you need for your first spark program
towardsdatascience.com
https://data-flair.training/forums/topic/what-is-meant-by-in-memory-processing-in-spark/
https://www.quora.com/Why-is-Spark-considered-in-memory-compared-to-Hadoop
Why is Spark considered "in-memory" compared to Hadoop?
Answer: Spark is a newer project, initially developed in 2012, at the AMPLab at UC Berkeley. It’s also a top-level Apache project focused on processing data in parallel across a cluster, but the biggest difference is that it works in-memory. Whereas Hado
www.quora.com
https://medium.com/swlh/apache-spark-is-fun-eadcaf141c02
Apache Spark Is Fun
A hands-on tutorial into Spark DataFrames.
medium.com
https://techvidvan.com/tutorials/fault-tolerance-in-spark/
Fault Tolerance in Spark: Self recovery property - TechVidvan
Fault Tolerance in Spark: introduction, how spark handles fault tolerance, high availability in spark and significance of spark fault tolerance.
techvidvan.com
https://stackoverflow.com/questions/31508083/difference-between-dataframe-dataset-and-rdd-in-spark
Difference between DataFrame, Dataset, and RDD in Spark
I'm just wondering what is the difference between an RDD and DataFrame (Spark 2.0.0 DataFrame is a mere type alias for Dataset[Row]) in Apache Spark? Can you convert one to the other?
stackoverflow.com
https://medium.com/analytics-vidhya/spark-rdd-low-level-api-basics-using-pyspark-a9a322b58f6
Spark RDD (Low Level API) Basics using Pyspark
Although it is recommended to learn and use High Level API(Dataframe-Sql-Dataset) for beginners, Low Level API -resilient distributed…
medium.com
https://blog.knoldus.com/understanding-the-working-of-spark-driver-and-executor/
Understanding the working of Spark Driver and Executor
This blog pertains to Apache SPARK, where we will understand how Spark's Driver and Executors communicate with each other to process a given job. So let’s get
blog.knoldus.com
'딥상어동의 딥한 프로그래밍 > Spark' 카테고리의 다른 글
| [Type hint] spark.DataFrame VS pd.DataFrame (0) | 2022.10.06 |
|---|---|
| [Spark] map, 그런데 flat을 곁들인 - flatMap (0) | 2022.08.28 |
| [mllib] Pyspark Kmeans 알고리즘 사용법 (0) | 2022.04.08 |
| [Pyspark] from pyspark.sql import * VS from pyspark.sql.functions import * (0) | 2022.04.07 |
| [PySpark] Python 내장 함수 사용시 발생하는 오류 (0) | 2021.07.21 |
제 블로그에 와주셔서 감사합니다! 다들 오늘 하루도 좋은 일 있으시길~~
포스팅이 좋았다면 "좋아요❤️" 또는 "구독👍🏻" 해주세요!
![[Type hint] spark.DataFrame VS pd.DataFrame](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FwJK4M%2FbtrNZpjPmA9%2FrTUX2EpBTmFCaquIvVN7I0%2Fimg.png)
![[Spark] map, 그런데 flat을 곁들인 - flatMap](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FcdId0h%2FbtrKpP1irHZ%2Ftb1QJJTM3rEjfdQnINkzvK%2Fimg.png)
![[mllib] Pyspark Kmeans 알고리즘 사용법](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FtzEI7%2FbtryEyqO1h2%2FMT5hZp7bKOHAWNqUzHP8F0%2Fimg.png)
![[Pyspark] from pyspark.sql import * VS from pyspark.sql.functions import *](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2Fbu0YXE%2FbtryE2ZuPLs%2FnM8YAOQ7cu7HBZl77lhaU1%2Fimg.png)