![[도서 리뷰] 머신러닝 실무 프로젝트](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2Fcv7nW9%2FbtrAj3gjsBL%2FgtlpfdyFoCwCgG6TiDjo6k%2Fimg.jpg)

"한빛미디어 <나는 리뷰어다> 활동을 위해서 책을 제공받아 작성된 서평입니다."

책의 제목처럼 이 책은 머신러닝으로 실무 프로젝트를 진행할 때 생길 수 있는 문제점이나 대처법 그리고 방법론 등에 대해서 다루고 있다.

책의 첫 시작은 비즈니스 문제를 머신러닝으로 정의하는 법 먼저 시작한다. sklearn, tensorflow, pytorch등 ML/DL 라이브러리가 상용화 되면서 알고리즘에 대한 접근성 자체는 충분히 높아졌지만, 알고리즘을 실제 비즈니스에 접목시키는 또 다른 문제이다. 책에서는 소비 전력 예측(ML 문제) - 공장 전력 소비량 최적화(비즈니스 문제), 사용자별 추천 상품 제시(ML 문제) - 매출 향상(비즈니스 문제)를 그 예시로 들고 있다.

비즈니스 문제와 관련된 항목을 지나면 "머신러닝을 사용하지 않는 방법 검토"에 대한 얘기가 나온다. 저자는 머신러닝 시스템이 다른 시스템보다 "기술 부채"가 크다는 얘기를 하고 있다. 즉, 비즈니스 관점에서 ML은 추가적인 비용을 수반하기 때문에 만약, ML을 사용하지 않고 해결할 수 있는 방법이 있다면 그걸 먼저 사용하라는 의미이다.

2, 3장에서는 머신러닝 알고리즘 및 평가 방법 등에 대한 얘기가 나온다. 개인적으로 "머신러닝으로 할 수 있는 일"이라는 제목 보다는 "머신러닝 알고리즘 소개"라는 제목이 더 잘어울리지 않나 싶다. 알고리즘에 대한 깊은 얘기는 하지 않고 기본적인 알고리즘 및 알고리즘 평가 방법 등에 대한 얘기를 한다. 머신러닝 학습자보다는 기존에 머신러닝에 대한 개념이 대략적으로 잡혀있는 사람이 한번쯤 살펴보고 지나가면 좋을 것 같은 챕터이다.

4장에서는 기존 시스템에 머신러닝 방법론을 통합하는 방법에 대해서 얘기가 나온다. 여기서 통합의 영역은 "데이터 처리"이다. 주로 기존에 수집하던 데이터를 어떤 단위로 처리해서 어떻게 학습시킬지에 대한 얘기가 나온다. 한가지 특이한점은 이 책에서는 배치 학습과 온라인 학습에 대한 용어를 재정의 했다는 것이다. 배치 학습은 "일괄 학습"으로 온라인 학습은 "순차 학습"으로 표현하고 있다. 아마, 배치(저장된 데이터를 일괄 처리 - 데이터 사이즈에 따라 학습시간 많이 소요될 수 있음)/온라인(실시간으로 처리되는 데이터를 순차적으로 학습) 두 학습 방법에서 데이터를 처리하는 방식이 다르기 때문에 이렇게 구분한 것 같다.
최종적으로 저자는 일괄 학습/순차 학습 한 가지만 이용하기 보다는 두 기법을 적절히 사용하는 것을 권장하고 있다.
일괄 학습 - 임의 간격 동안 쌓인 데이터를 통해 모델 학습후 베이스 라인 업데이트
순차 학습(미니 배치) - 추가 학습을 통해 모델 최적화

6장에서는 지속적 학습과 그 수단으로 MLOps에 대한 얘기를 하고 있다. 지속적 학습이 필요한 이유는 시간이 흐름에 따라 입력 데이터의 특성이 달라질 수 있기 때문이다. 이어서 "지속적 학습이 잘 이루어지고 있는지"에 대해 저자가 어떤 지표를 통해 판단하는지에 대한 얘기가 나온다. 저자는 단순 AUC나 로그 손실 체킹 보다는 RIG(상대적 정보 획득)을 추적한다고 한다. 평균 값만을 이용해 추정했을 때 RIG값이 0이 된다고 하는데 이 0을 기점으로 상대적으로 정보 획득이 더 용이한지/불리한지를 판단하는 것 같다. 주관적이 생각이지만 회귀 분석의 R^2와도 유사하다는 생각이 든다.

7장에서는 머신러닝 기반 정책 성과 판단하기에 관련된 내용이 나온다. 관련하여 평균처리효과(ATE), 무작위 비교 시험(RCT)등에 대한 용어를 설명하다. 데이터 분석의 주요 활용처 중 하나가 효과 검증이기 때문에 7장의 내용은 머신러닝 적용의 관점 뿐만 아니라 데이터 분석의 관점에서도 한번쯤 자세히 읽어보면 좋을 것 같다.
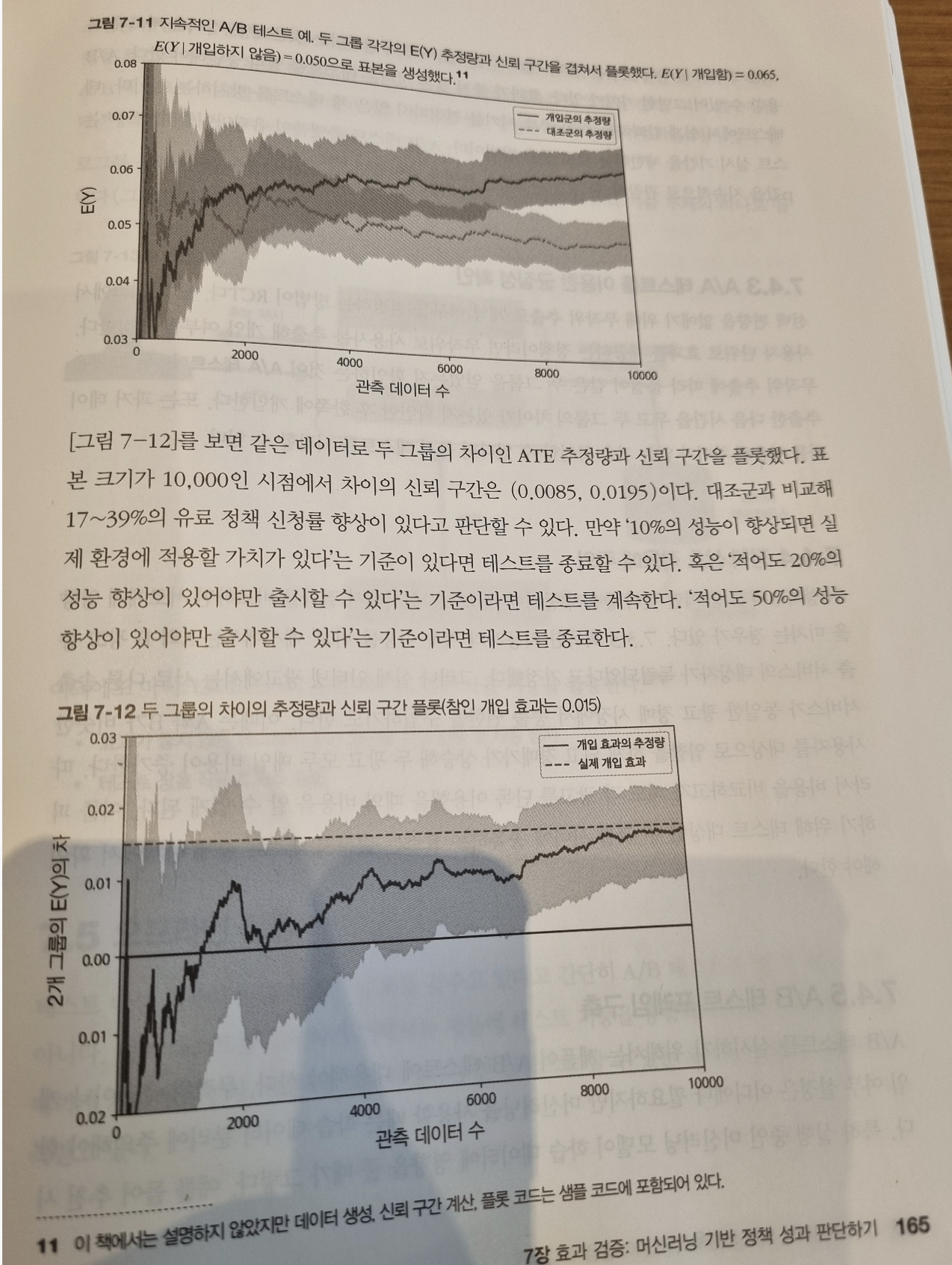
특히, A/B테스트에 대한 종료 시점을 어디서 판단해야할지에 관련된 내용이 있어서 실무에 도움이 될 것 같았다. 책에서는 개입군과 대조군의 추정량을 비교해서 baseline(10%성능 향상)을 넘어가는 지점을 종료 시점으로 설명하고 있다.
8장은 모델 해석과 관련된 내용으로 아무래도 해석력이 높은 모델 몇 가지를 예시로 들어 설명하고 있다. 해석력이 높은 대표적인 모델은 회귀분석이 있다. 왜냐하면, 회귀분석의 경우 회귀계수를 구할 수 있기 때문이다. 회귀계수의 부호만 살펴보더라도 종속 변수에 어떤 영향을 끼쳤는지를 알아볼 수 있다. 더불어, Feature Importance의 단점을 개선한 SHAP Value에 대해서도 소개하고 있다.
파트2에서는 머신러닝 실무 프로젝트에 대한 사례가 자세히 나온다. ML을 실행하지 않고 진행할 수 있는 프로젝트 먼저 시작한다는 점이 개인적으로 마음에 들었다. 왜냐하면, 그만큼 가볍고 간단하게 시작할 수 있기 때문이다.
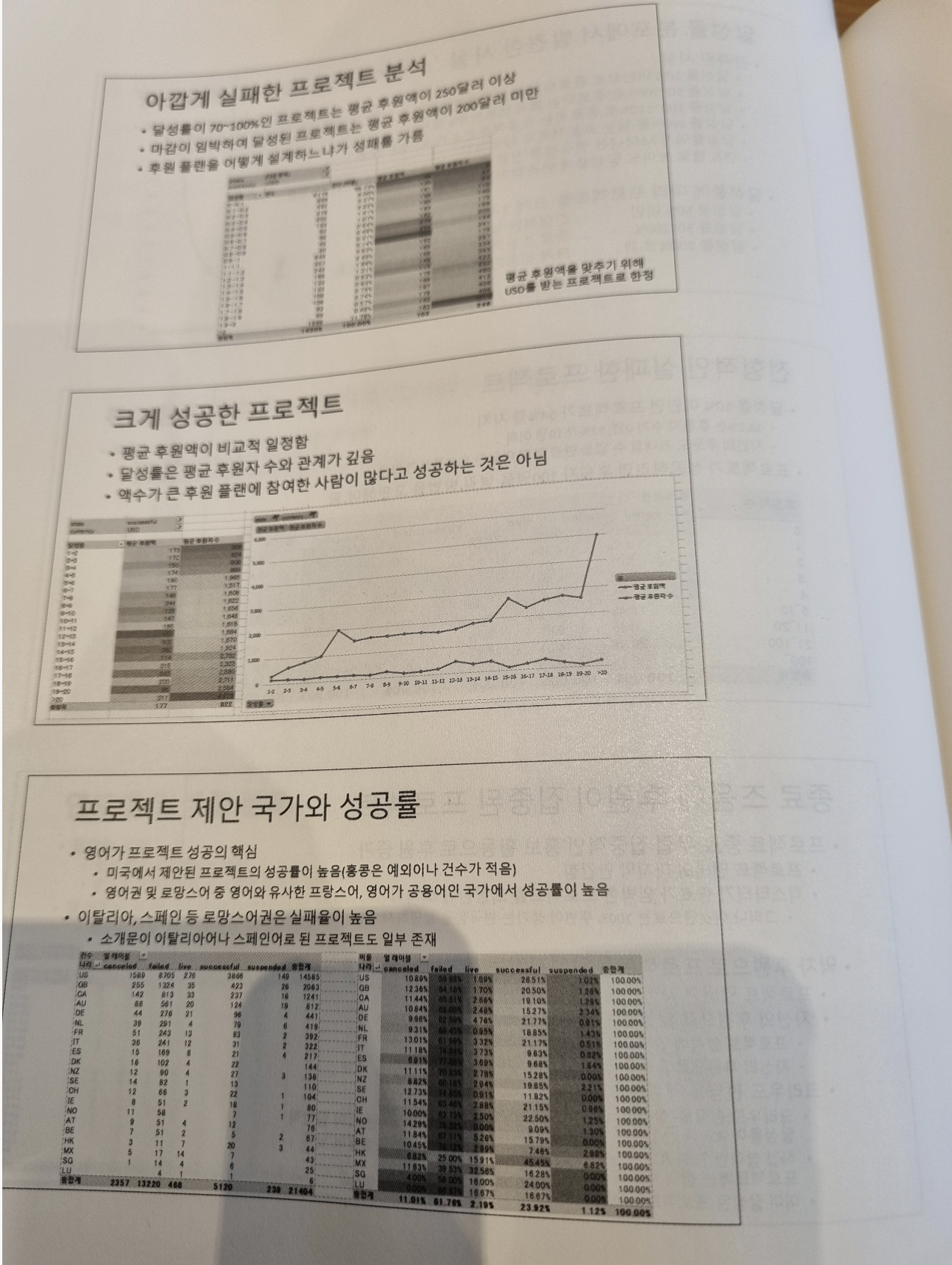
특히, 킥스타터라는 플랫폼의 API를 활용해 성공하는 프로젝트와 실패하는 프로젝트를 비교해보고 성공할 수 있는 전략을 마련하는 점이 인상깊었다. 이런 프로젝트는 관심있는 분야 + 약간의 코딩 지식만 있으면 언제든지 적용해볼 수 있을 것 같다.
또한, 업리프트 모델링을 이용한 마케팅 리소스 효율화에 관련된 얘기도 있어 인과추론에 관심이 있으신 분들도 한번쯤 재밌게 읽어볼 수 있을 것 같다.
총평
이 책 역시 지난 시간에 리뷰한 SQL쿡북과 마찬가지로 Learner보다느 User에게 걸맞는 책이다. 이제 막 머신러닝 알고리즘 및 데이터 분석에 입문한 사람들이 프로젝트를 시작하기 전에 참고 서적으로 활용해보면 좋을 것 같다. 그 외에 현업에서 실제 데이터 관련된 업무를 진행하시는 분들도 업무를 진행하기전 프로젝트 사례 혹은 체크 사항들에 대해 한번쯤 확인해보면 많은 도움이 될 것 같다. 최신 기법에 대한 내용은 없으나, 과거 그리고 현재까지도 유용하게 사용하고 있는 기법들을 실무 혹은 프로젝트에 어떻게 녹여야할지에 대해 잘 다루고 있는 책이다. 만약, 시간이 없다면 파트2라도 한번 읽어보시길 추천드린다.
'나라는 존재 > 책' 카테고리의 다른 글
| 원칙의 어깨에 올라서서 더 넓은 세상을 바라보자 (6) | 2023.06.03 |
|---|---|
| 책속 한마디 - 스톱 씽킹 (0) | 2023.04.02 |
| [도서 리뷰] SQL 쿡북 (2) | 2022.02.22 |
| [책 속 한마디] 여덟 단어 (0) | 2021.03.22 |
| [서평] 원씽 (the ONE thing) (0) | 2021.02.12 |
제 블로그에 와주셔서 감사합니다! 다들 오늘 하루도 좋은 일 있으시길~~
포스팅이 좋았다면 "좋아요❤️" 또는 "구독👍🏻" 해주세요!


![[도서 리뷰] SQL 쿡북](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FbhXHPR%2Fbtrt4gtzmd7%2Fi8W5gScENPOBkYHTA0InW0%2Fimg.jpg)
![[책 속 한마디] 여덟 단어](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FdHQDxQ%2Fbtq0PcFqmNG%2FKUhkIHEa8kG8fwFv4HhC71%2Fimg.jpg)