![[Spark] map, 그런데 flat을 곁들인 - flatMap](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FcdId0h%2FbtrKpP1irHZ%2Ftb1QJJTM3rEjfdQnINkzvK%2Fimg.png)


핵심 내용
Spark를 사용하며, 고수준API인 Dataframe객체를 이용하다 보니 RDD 함수를 사용할 일이 잘 없었다. 그러다가, 최근 들어 flatMap을 유용하게 사용하고 있는데 오늘은 flatMap 함수에 대해서 다루어 보려고 한다.
글의 목표
- Map 함수에 대해 이해하기
- Map함수와 flatMap함수의 차이 이해하기
- flatMap함수를 이용하여 explode해보기
(본 글에서 RDD에 대해 따로 다루지는 않습니다. 관련된 내용은 아래 글을 참고해주세요.)
https://gibles-deepmind.tistory.com/136
[PySpark] 자료 구조와 연산 원리 - 스파크 누구냐 넌?
핵심내용 스파크의 고유한 자료 구조와 연산 특징에 대해서 다루어보고자 합니다. ※스파크 설치 방법에 대해서는 다루지 않습니다. 대신 간단한 데이터브릭스 샘플 코드를 포함합니다. 본 글
gibles-deepmind.tistory.com
# 데이터 셋 불러오기
import pandas as pd
titanic_pandas = pd.read_csv("https://raw.githubusercontent.com/datasciencedojo/datasets/master/titanic.csv")
spark_df = spark.createDataFrame(titanic_pandas)
1. Map함수
예를 들어, 성별이 잘못 기입되어 있다고 가정하자. 이때, map함수를 사용하면 아래와 같이 모든 레코드들에 대해 하나씩 변환할 수 있다. 즉, Map이전의 행 수와 = Map이후의 행 수가 동일하다.
print(spark_df.select("Sex").rdd.collect()[:5])
print(spark_df.select("Sex").rdd.map(lambda x: 'female' if x == 'male' else 'female').collect()[:5])확인 결과, male에서 female / female에서 male로 모든 값들이 하나씩 변경된 것을 확인할 수 있다. 잠깐! 여기서 한 가지 짚고 넘어갈 부분이 있다. Map을 통과하는 lambda함수의 인자 x의 자료형은 "Row"이다. rdd내의 레코드라고 생각하면 편할 것 같다. 본 코드에서는 원소의 개수가 한 개인 Row를 상정했지만, Row내에는 여러개의 원소가 있을 수 있다. 아래와 같이 말이다.
print(spark_df.select("Pclass", "Survived").rdd.collect()[:5])
print(spark_df.select("Pclass", "Survived").rdd.map(lambda x: 'female' if x == 'male' else 'female').collect()[:5])
map함수를 이용해 두 열의 값들을 합할 수도 있다.
print(spark_df.select("Pclass").rdd.collect()[:5])
print(spark_df.select("Survived").rdd.collect()[:5])
print(spark_df.select("Pclass", "Survived").rdd.map(lambda x: x[0] + x[1]).collect()[:5])위와 같이 x[0]와, x[1]으로 인덱싱이 가능하다. 왜냐하면, Row객체를 이용하기 때문
2. flatMap 함수
flatMap 함수의 설명을 읽다보면 이런 얘기가 나온다.
Map은 1:1대응 관계이지만, flatMap은 1:1도 1:Many의 관계도 가능하다.
이게 무슨 얘기일까? 결과를 통해 살펴보자.
spark_df.select("Pclass").rdd.flatMap(lambda x: [x, x]).collect()위와 같이 flatMap을 사용하자 똑같은 결과가 2번씩 반복되는 것을 알 수 있다. 즉, 하나의 input = x를 통해 2개의 output = multiple output이 생긴 것이다.
print(spark_df.count())
print(spark_df.select("Pclass").rdd.flatMap(lambda x: [x, x]).count())
원본에 비해 row가 2배로 증가한 것을 볼 수 있다. 똑같은 내용을 map함수에 적용해보자.
spark_df.select("Pclass").rdd.map(lambda x: [x, x]).collect()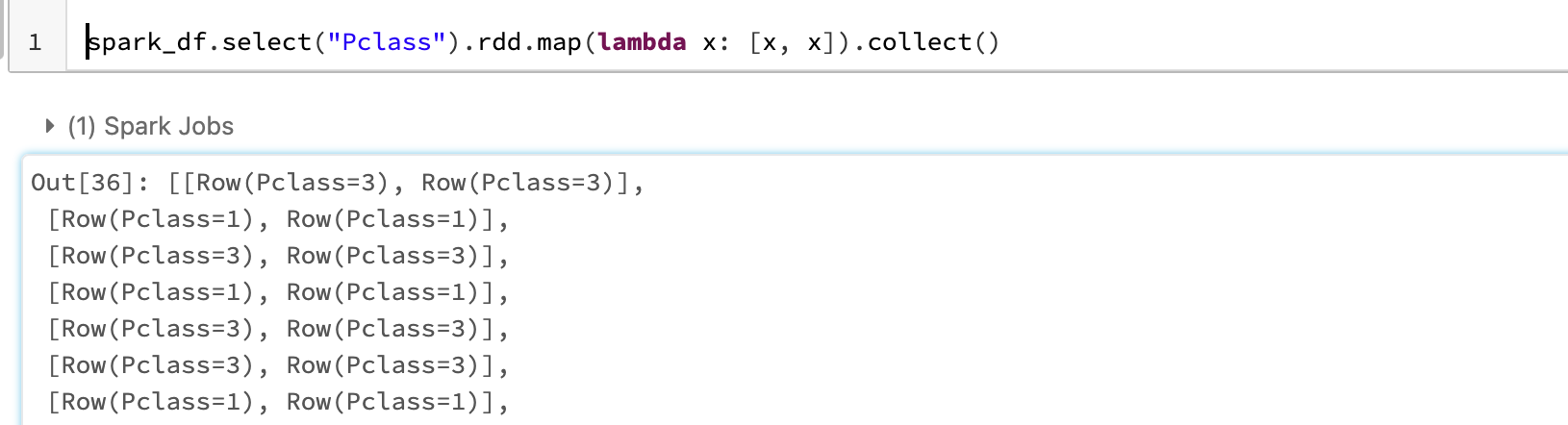
동일한 내용이 리스트 안에 들어가 있는 것을 확인할 수 있다. 한 가지 더, flatMap의 output 1d array였으나, Map의 output은 list가 그대로 보존된 것을 볼 수 있다.
다시 행수를 비교해보자.
print(spark_df.count())
print(spark_df.select("Pclass").rdd.map(lambda x: [x, x]).count())
원본과 똑같은 것을 알 수 있다. 왜? flat을 시키지 않았고 이에 따라 원본 input과의 1:1대응 관계가 유지되었기 때문이다.
3. flatMapValues를 explode처럼 이용해보기
spark_dict = [{'aaa':'a', 'num_list':[1, 2, 3]},
{'aaa':'b', 'num_list':[4, 5, 6]}]
df_sample = spark.createDataFrame(spark_dict, ['aaa', 'num_list'])
현재, 위 데이터 는 현재 2x2 Matrix이다. 여기서, num_list를 flat하게 만들어 6x2 Matrix를 만들어보자. 보통은 이런 상황일 때, explode를 이용한다.
df_sample.withColumn("exploded", explode("num_list")).select("aaa", "exploded").show()
flatMapValues를 이용해서도 똑같은 결과를 낼 수 있다.
df_sample.rdd.flatMapValues(lambda x:x).toDF(['aaa', 'num_list']).show()
Ref.
https://spark.apache.org/docs/3.1.1/api/python/reference/api/pyspark.RDD.flatMapValues.html
pyspark.RDD.flatMapValues — PySpark 3.1.1 documentation
Pass each value in the key-value pair RDD through a flatMap function without changing the keys; this also retains the original RDD’s partitioning. Examples >>> x = sc.parallelize([("a", ["x", "y", "z"]), ("b", ["p", "r"])]) >>> def f(x): return x >>> x.f
spark.apache.org
https://sparkbyexamples.com/pyspark/pyspark-flatmap-transformation/
PySpark flatMap() Transformation - Spark by {Examples}
PySpark flatMap() is a transformation operation that flattens the RDD/DataFrame (array/map DataFrame columns) after applying the function on every element and returns a new PySpark RDD/DataFrame. In this article, you will learn the syntax and usage of the
sparkbyexamples.com
'딥상어동의 딥한 프로그래밍 > Spark' 카테고리의 다른 글
| [Type hint] spark.DataFrame VS pd.DataFrame (0) | 2022.10.06 |
|---|---|
| [PySpark] 자료 구조와 연산 원리 - 스파크 누구냐 넌? (4) | 2022.06.28 |
| [mllib] Pyspark Kmeans 알고리즘 사용법 (0) | 2022.04.08 |
| [Pyspark] from pyspark.sql import * VS from pyspark.sql.functions import * (0) | 2022.04.07 |
| [PySpark] Python 내장 함수 사용시 발생하는 오류 (0) | 2021.07.21 |
제 블로그에 와주셔서 감사합니다! 다들 오늘 하루도 좋은 일 있으시길~~
포스팅이 좋았다면 "좋아요❤️" 또는 "구독👍🏻" 해주세요!
![[Type hint] spark.DataFrame VS pd.DataFrame](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FwJK4M%2FbtrNZpjPmA9%2FrTUX2EpBTmFCaquIvVN7I0%2Fimg.png)
![[PySpark] 자료 구조와 연산 원리 - 스파크 누구냐 넌?](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FbjIGfE%2FbtrFIc7jjiO%2FGC0CEDGCAuxW1gqbthEKrk%2Fimg.png)
![[mllib] Pyspark Kmeans 알고리즘 사용법](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FtzEI7%2FbtryEyqO1h2%2FMT5hZp7bKOHAWNqUzHP8F0%2Fimg.png)
![[Pyspark] from pyspark.sql import * VS from pyspark.sql.functions import *](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2Fbu0YXE%2FbtryE2ZuPLs%2FnM8YAOQ7cu7HBZl77lhaU1%2Fimg.png)